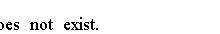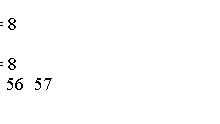Java教程 第76页 Java XML教程 – Java DOM简介 DOM是标准的树结构,其中每个节点包含来自XML结构的一个组件。 XML文档中两种最常见的节点类型是元素节点和文本节点。 使用Java DOM API,我们可以创建节点,删除节点,更改其内容,并遍历节点层次结构。 何时使用DOM 文档对象模型标准是为XML文档操作而设计的。 DOM的用意是语言无关的。Java的DOM解析器没有利用Java的面向对象的特性优势。 混合内容模型 文本和元素在DOM层次结构中混合。这种结构在DOM模型中称为混合内容。 例如,我们有以下xml结构: <yourTag>This is an <bold>important</bold> test.</yourTag> DOM节点的层级如下,其中每行代表一个节点: ELEMENT: yourTag + TEXT: This is an + ELEMENT: bold + TEXT: important + TEXT: test. yourTag 元素包含文本,后跟一个子元素,后跟另外的文本。 节点类型 为了支持混合内容,DOM节点非常简单。标签元素的“内容”标识它是的节点的类型。 例如,<yourTag> 节点内容是元素 yourTag的名称。 DOM节点API定义 nodeValue(), nodeType()和 nodeName()方法。 对于元素节点< yourTag> nodeName()返回yourTag,而nodeValue()返回null。 对于文本节点 + TEXT:这是一个nodeName()返回#text,nodeValue()返回“This is an”。 例子 以下代码显示了如何使用DOM解析器来解析xml文件并获取一个 org.w3c.dom.Document 对象。 import java.io.File; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; public class Main { public static void main(String[] args) throws Exception { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = null; db = dbf.newDocumentBuilder(); Document doc = db.parse(new File("games.xml")); } } 例2 以下代码显示如何执行DOM转储。 import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.ErrorHandler; import org.xml.sax.InputSource; import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; public...
2024-04-01
Java XML教程 – Java SAX API简介 Java SAX XML解析器代表Simple API for XML(SAX)解析器。 SAX是一种用于访问XML文档的事件驱动的串行访问机制。 此机制经常用于传输和接收XML文档。 SAX是一种状态独立处理,其中元素的处理不依赖于其他元素。StAX是状态相关处理。 SAX是一个事件驱动模型。 当使用SAX解析器时,我们提供了回调方法,并且解析器在读取XML数据时调用它们。 在SAX中,我们不能回到文档的早期部分,我们只能处理元素逐个元素,从开始到结束。 何时使用SAX SAX是快速和高效的,并且它对于状态无关的过滤是有用的。当遇到元素标记和时,SAX解析器调用一个方法当发现文本时调用不同的方法。 SAX比DOM要求更少的内存,因为SAX不像DOM那样创建XML数据的内部树结构。 使用SAX解析XML文件 在下面我们将看到一个输出所有SAX事件的演示应用程序。它是从包中扩展 DefaultHandler org.xml.sax.helpers 如下。 public class Main extends DefaultHandler { 以下代码设置了解析器并启动它: SAXParserFactory spf = SAXParserFactory.newInstance(); spf.setNamespaceAware(true); spf.setValidating(true); parser = spf.newSAXParser(); parser.parse(file, this); 这些代码行创建一个SAXParserFactory实例,由 javax.xml.parsers.SAXParserFactory 系统属性的设置决定。 工厂被设置为支持XML命名空间将 setNamespaceAware 设置为 true 然后通过 newSAXParser()方法从工厂获取SAXParser实例。 然后它处理开始文档和结束文档事件: public void startDocument() { System.out.println("Start document: "); } public void endDocument() { System.out.println("End document: "); } 之后,它使用 System.out.println 打印消息一旦方法是由解析器调用。 遇到开始标记或结束标记时,根据需要,将标记的名称作为String传递到 startElement 或 endElement 方法。 当遇到开始标记时,它定义的任何属性都会在 Attributes 列表中传递。 public void startElement(String uri, String localName, String qname, Attributes attr) { System.out.println("Start element: local name: " + localName + " qname: " + qname + " uri: " + uri); } 元素中的字符作为字符数组传递,以及字符数和指向第一个字符的数组的偏移量。 public void characters(char[] ch, int start, int...
2024-04-01
Java XML教程 – Java XML API SAX API 下面是关键的SAX API的摘要: 类 用法 SAXParserFactory 创建由系统属性javax.xml.parsers.SAXParserFactory确定的解析器的实例。 SAXParser SAXParser接口定义了几个重载的parse()方法。 SAXReader SAXParser包装一个SAXReader,并从SAXParser的getXMLReader()方法返回。 DefaultHandler DefaultHandler实现了ContentHandler,ErrorHandler,DTDHandler,和EntityResolver接口。 通过使用DefaultHandler,我们可以只覆盖我们需要的那些。 ContentHandler 此接口定义回调方法,如startDocument,endDocument,startElement和endElement。 这些方法在识别XML标记时调用。它还定义了被调用的方法characters()当解析器遇到XML元素中的文本时。它定义被调用的processingInstruction()当解析器遇到内联处理指令时。 ErrorHandler 它使用error(),fatalError()和warning()方法来响应各种解析错误。 默认的错误处理程序只会抛出致命错误和的异常忽略验证错误。 DTDHandler 用于处理DTD EntityResolver 它的resolveEntity()方法用于标识数据。 我们通常实现大多数 ContentHandler 方法。 为了提供更稳健的实现,我们可以从ErrorHandler实现方法。 SAX包 SAX解析器在下表中列出的软件包中定义。 包 描述 org.xml.sax 定义SAX接口。 org.xml.sax.ext 定义用于更高级SAX处理的SAX扩展。 org.xml.sax.helpers 定义SAX API的辅助类。 javax.xml.parsers 定义SAXParserFactory类,它返回SAXParser。 DOM API javax.xml.parsers.DocumentBuilderFactory 类返回一个 DocumentBuilder 实例。 我们使用 DocumentBuilder 实例来产生一个 Document 对象退出XML文档。 构建器由系统属性 javax.xml.parsers.DocumentBuilderFactory 确定。 DocumentBuilder 中的 newDocument()方法可以创建一个实现 org.w3c.dom.Document 接口的空Document。 我们可以使用其中一个构建器的解析方法来创建一个 Document 从现有的XML文档。 DOM包 文档对象模型实现在中定义下表中列出的软件包。 包 描述 org.w3c.dom 定义XML文档的DOM编程接口。 javax.xml.parsers 定义DocumentBuilderFactory类和DocumentBuilder类。 XSLT API TransformerFactory 创建一个 Transformer 对象。 XSLT API在下表中显示的包中定义。 包 描述 javax.xml.transform 定义TransformerFactory和Transformer类。 我们可以从变换器对象调用transform()方法来进行变换。 javax.xml.transform.dom 用于从DOM创建输入和输出对象的类。 javax.xml.transform.sax 用于从SAX解析器创建输入对象和从SAX事件处理程序输出对象的类。 javax.xml.transform.stream 用于从I / O流创建输入对象和输出对象的类。 StAX APIs StAX为开发人员提供了SAX和DOM解析器的替代方法。 StAX可以用更少的内存进行高性能流过滤,处理和修改。 StAX是用于流式XML处理的标准的双向拉解析器接口。 StAX提供比SAX更简单的编程模型,并且比DOM更高的内存效率。 StAX可以解析和修改XML流作为事件。 StAX包 StAX APIs在下表中显示的包中定义。 包 描述 javax.xml.stream 定义迭代XML文档元素的XMLStreamReader接口。 定义XMLStreamWriter接口,指定如何写入XML。 javax.xml.transform.stax 提供StAX特定的转换API。
2024-04-01
Java IO教程 – Java令牌 Java有一些实用程序类,让我们将一个字符串分解成称为令牌的部分。 我们通过定义分隔符字符来定义被认为是令牌的字符序列。 StringTokenizer类位于java.util包中。 StreamTokenizer类位于java.io包中。 StringTokenizer将字符串拆分成令牌,而StreamTokenizer让我们在基于字符的流中访问令牌。 StringTokenizer StringTokenizer对象根据您对定界符的定义将字符串拆分为标记。它一次返回一个令牌。 我们还可以随时更改分隔符。我们可以通过指定字符串并接受默认分隔符来创建一个StringTokenizer,它是空格,制表符,换行符,回车符和换行符(“\t \n \r \f”)如下: StringTokenizer st = new StringTokenizer("here is my string"); 我们可以在创建StringTokenizer时指定自己的分隔符,如下所示:下面的代码使用空格,逗号和分号作为分隔符。 String delimiters = " ,;"; StringTokenizer st = new StringTokenizer("my text...", delimiters); 我们可以使用hasMoreTokens()方法来检查是否有更多的令牌和nextToken()方法从字符串中获取下一个令牌。 我们还可以使用String类的split()方法将字符串拆分为基于分隔符的令牌。 split()方法接受正则表达式作为分隔符。 以下代码显示如何使用StringTokenizer和String类的split()方法。 import java.util.StringTokenizer; public class Main { public static void main(String[] args) { String str = "This is a test, this is another test."; String delimiters = " ,"; // a space and a comma StringTokenizer st = new StringTokenizer(str, delimiters); System.out.println("Tokens using a StringTokenizer:"); String token = null; while (st.hasMoreTokens()) { token = st.nextToken(); System.out.println(token); } } } 上面的代码生成以下结果。 StreamTokenizer 要根据标记的类型区分标记,请使用StreamTokenizer类。 import static java.io.StreamTokenizer.TT_EOF; import static java.io.StreamTokenizer.TT_NUMBER; import static java.io.StreamTokenizer.TT_WORD; import java.io.IOException; import java.io.StreamTokenizer; import java.io.StringReader; public class Main {...
2024-04-01
Java IO教程 – Java打印流 PrintStream类是输出流的具体装饰器。 PrintStream可以以合适的格式打印任何数据类型值,基本或对象。 PrintStream可以将数据写入输出流不抛出IOException。 如果一个方法抛出一个IOException,PrintStream设置一个内部标志,而不是抛出异常给调用者。可以使用其checkError()方法检查该标志,如果在方法执行期间发生IOException,则返回true。 PrintStream具有自动刷新功能。我们可以在其构造函数中指定它应该自动刷新写入它的内容。 如果我们将auto-flush标志设置为true,当写入一个字节数组时,PrintStream将刷新它的内容,它的一个重载的println()方法用于写入数据,一个换行符被写入,或一个字节(‘\n’)。 import java.io.File; import java.io.FileNotFoundException; import java.io.PrintStream; public class Main { public static void main(String[] args) { String destFile = "luci3.txt"; try (PrintStream ps = new PrintStream(destFile)) { ps.println("test"); ps.println("test1"); ps.println("test2"); ps.print("test3"); // flush the print stream ps.flush(); System.out.println("Text has been written to " + (new File(destFile).getAbsolutePath())); } catch (FileNotFoundException e1) { e1.printStackTrace(); } } } 上面的代码生成以下结果。
2024-04-01
Java IO教程 – Java文件输出流 创建输出流 要写入文件,我们需要创建一个FileOutputStream类的对象,它将表示输出流。 // Create a file output stream String destFile = "test.txt"; FileOutputStream fos = new FileOutputStream(destFile); 当写入文件时,如果文件不存在,Java会尝试创建文件。我们必须准备好处理这个异常,将代码放在try-catch块中,如下所示: try { FileOutputStream fos = new FileOutputStream(srcFile); }catch (FileNotFoundException e){ // Error handling code goes here } 如果文件包含数据,数据将被擦除。为了保留现有数据并将新数据附加到文件,我们需要使用FileOutputStream类的另一个构造函数,它接受一个布尔标志,用于将新数据附加到文件。 要将数据附加到文件,请在第二个参数中传递true,使用以下代码。 FileOutputStream fos = new FileOutputStream(destFile, true); 写数据 FileOutputStream类有一个重载的write()方法将数据写入文件。我们可以使用不同版本的方法一次写入一个字节或多个字节。 通常,我们使用FileOutputStream写入二进制数据。 要向输出流中写入诸如“Hello”的字符串,请将字符串转换为字节。 String类有一个getBytes()方法,该方法返回表示字符串的字节数组。我们给FileOutputStream写一个字符串如下: String text = "Hello"; byte[] textBytes = text.getBytes(); fos.write(textBytes); 要插入一个新行,使用line.separator系统变量如下。 String lineSeparator = System.getProperty("line.separator"); fos.write(lineSeparator.getBytes()); 我们需要使用flush()方法刷新输出流。 fos.flush(); 刷新输出流指示如果任何写入的字节被缓冲,则它们可以被写入数据宿。 关闭输出流类似于关闭输入流。我们需要使用close()方法关闭输出流。 // Close the output stream fos.close(); close()方法可能抛出一个IOException异常。如果我们希望自动关闭tit,请使用try-with-resources创建输出流。 以下代码显示如何将字节写入文件输出流。 import java.io.File; import java.io.FileOutputStream; public class Main { public static void main(String[] args) { String destFile = "luci2.txt"; // Get the line separator for the current platform String lineSeparator = System.getProperty("line.separator"); String line1 = "test"; String line2 = "test1"; String line3...
2024-04-01
Java IO教程 – Java文件 File类的对象是文件或目录的路径名的抽象表示。 创建文件 我们可以从中创建一个 File 对象 路径名 父路径名和子路径名 URI(统一资源标识符) 我们可以使用File类的以下构造函数之一创建一个文件: File(String pathname) File(File parent, String child) File(String parent, String child) File(URI uri) 如果我们有一个文件路径名字符串test.txt,我们可以创建一个抽象路径名作为下面的代码。 File dummyFile = new File("test.txt"); 名为test.txt的文件不必存在,以使用此语句创建File对象。 dummyFile对象表示抽象路径名,它可能指向或可能不指向文件系统中的真实文件。 File类有几个方法来处理文件和目录。 使用File对象,我们可以创建新文件,删除现有文件,重命名文件,更改文件的权限等。 File类中的isFile()和isDirectory()告诉File对象是否表示文件或目录。 当前工作目录 JVM的当前工作目录是根据我们如何运行java命令来设置的。 我们可以通过读取user.dir系统属性来获取JVM的当前工作目录,如下所示: String workingDir = System.getProperty("user.dir"); 使用System.setProperty()方法更改当前工作目录。 System.setProperty("user.dir", "C:\\myDir"); 要在Windows上指定C:\\ test作为user.dir系统属性值,我们运行如下所示的程序: java -Duser.dir=C:\test your-java-class 文件的存在 我们可以使用File类的exists()方法检查File对象的抽象路径名是否存在。 boolean fileExists = dummyFile.exists(); 完整源代码 import java.io.File; public class Main { public static void main(String[] argv) { // Create a File object File dummyFile = new File("dummy.txt"); // Check for the file"s existence boolean fileExists = dummyFile.exists(); if (fileExists) { System.out.println("The dummy.txt file exists."); } else { System.out.println("The dummy.txt file does not exist."); } } } 上面的代码生成以下结果。 路径 绝对路径在文件系统上唯一标识文件。规范路径是唯一标识文件系统上文件的最简单路径。 我们可以使用getAbsolutePath()和getCanonicalPath()方法来分别获得由File对象表示的绝对路径和规范路径。 import java.io.File; import java.io.IOException; public class Main...
2024-04-01
Java IO教程 – Java阅读器和写入器 Java阅读器和写入器是基于字符的流。 当我们要从数据源读取基于字符的数据时,使用读取器。当我们想要写基于字符的数据时使用写入器。 如果我们有一个流提供字节,我们想通过将这些字节解码为字符读取字符,我们应该使用InputStreamReader类。 例如,如果我们有一个名为iso的InputStream对象,并且我们想要获取一个Reader对象实例,我们可以这样做: Reader reader = new InputStreamReader(iso); 如果我们知道在基于字节的流中使用的编码,我们可以在创建Reader对象时指定它,如下所示: Reader reader = new InputStreamReader(iso, "US-ASCII"); 类似地,我们可以创建一个Writer对象,从基于字节的输出流中吐出字符,如下所示,假设oso是一个OutputStream对象: 以下代码使用平台默认编码从OutputStream创建Writer对象。 Writer writer = new OutputStreamWriter(oso); 使用“US-ASCII”编码从OutputStream创建Writer对象 Writer writer = new OutputStreamWriter(oso, "US-ASCII"); 样本 import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; public class Main { public static void main(String[] args) { String destFile = "test.txt"; try (BufferedWriter bw = new BufferedWriter(new FileWriter(destFile))) { bw.append("test"); bw.newLine(); bw.append("test1"); bw.newLine(); bw.append("test2"); bw.newLine(); bw.append("test3"); bw.flush(); } catch (Exception e2) { e2.printStackTrace(); } } } 以下代码从test.txt文件中读取文本。 import java.io.BufferedReader; import java.io.FileReader; public class Main { public static void main(String[] args) throws Exception{ String srcFile = "test.txt"; BufferedReader br = new BufferedReader(new FileReader(srcFile)); String text = null; while ((text = br.readLine()) != null) { System.out.println(text); } br.close();...
2024-04-01
Java IO教程 – Java随机访问文件 使用随机访问文件,我们可以从文件读取以及写入文件。 使用文件输入和输出流的读取和写入是顺序过程。 使用随机访问文件,我们可以在文件中的任何位置读取或写入。 RandomAccessFile类的一个对象可以进行随机文件访问。我们可以读/写字节和所有原始类型的值到一个文件。 RandomAccessFile可以使用其readUTF()和writeUTF()方法处理字符串。 RandomAccessFile类不在InputStream和OutputStream类的类层次结构中。 模式 可以在四种不同的访问模式中创建随机访问文件。访问模式值是一个字符串。它们列出如下: 模式 含义 “r” 文件以只读模式打开。 “rw” 该文件以读写模式打开。 如果文件不存在,则创建该文件。 “rws” 该文件以读写模式打开。 对文件的内容及其元数据的任何修改立即被写入存储设备。 “rwd” 该文件以读写模式打开。 对文件内容的任何修改立即写入存储设备。 读和写 我们通过指定文件名和访问模式来创建RandomAccessFile类的实例。 RandomAccessFile raf = new RandomAccessFile("randomtest.txt", "rw"); 随机访问文件具有文件指针,当我们从其读取数据或向其写入数据时,该文件指针向前移动。 文件指针是我们下一次读取或写入将开始的光标。 其值指示光标与文件开头的距离(以字节为单位)。 我们可以通过使用其getFilePointer()方法来获取文件指针的值。 当我们创建一个RandomAccessFile类的对象时,文件指针被设置为零。 我们可以使用seek()方法将文件指针设置在文件中的特定位置。 RandomAccessFile的length()方法返回文件的当前长度。我们可以通过使用其setLength()方法来扩展或截断文件。 例子 以下代码显示如何使用RandomAccessFile对象读取和写入文件。 import java.io.File; import java.io.IOException; import java.io.RandomAccessFile; public class Main { public static void main(String[] args) throws IOException { String fileName = "randomaccessfile.txt"; File fileObject = new File(fileName); if (!fileObject.exists()) { initialWrite(fileName); } readFile(fileName); readFile(fileName); } public static void readFile(String fileName) throws IOException { RandomAccessFile raf = new RandomAccessFile(fileName, "rw"); int counter = raf.readInt(); String msg = raf.readUTF(); System.out.println(counter); System.out.println(msg); incrementReadCounter(raf); raf.close(); } public static void incrementReadCounter(RandomAccessFile raf) throws IOException { long currentPosition = raf.getFilePointer(); raf.seek(0); int counter =...
2024-04-01
Java IO教程 – Java缓冲区读写 缓冲区读取 有两种方法从缓冲区读取数据: 绝对位置 相对位置 使用四个版本重载的get()方法用于从缓冲区读取数据。 get(int index)返回给定索引处的数据。 get()从缓冲区中的当前位置返回数据,并将位置增加1。 get(byte [] destination,int offset,int length)从缓冲区中批量读取数据。 它从缓冲区的当前位置读取长度字节数,并将它们放在从指定偏移量开始的指定目标数组中。 get(byte [] destination)通过从缓冲区的当前位置读取数据并且每次读取数据元素时将当前位置递增1来填充指定的目标数组。 缓冲区写入 使用重载五个版本的put()方法将数据写入缓冲区。 put(int index,byte b)将指定的b数据写入指定的索引。 调用此方法不会更改缓冲区的当前位置。 put(byte b)将指定的字节写入缓冲区的当前位置,并将位置递增1。 put(byte [] source,int offset,int length)将起始于偏移量的源数组的字节长度写入从当前位置开始的缓冲区。 如果缓冲区中没有足够的空间来写入所有字节,它会抛出BufferOverflowException。 缓冲区的位置按长度增加。 put(byte [] source)与调用put(byte [] source,0,source.length)相同。 ByteBuffer put(ByteBuffer src)从指定的字节缓冲区src读取剩余的字节,并将它们写入缓冲区。 如果目标缓冲区中的剩余空间小于源缓冲区中的剩余字节,则抛出运行时BufferOverflowException。 以下代码显示如何写入缓冲区和从缓冲区读取。 import java.nio.ByteBuffer; public class Main { public static void main(String[] args) { ByteBuffer bb = ByteBuffer.allocate(8); printBufferInfo(bb); for (int i = 50; i < 58; i++) { bb.put((byte) i); } printBufferInfo(bb); } public static void printBufferInfo(ByteBuffer bb) { int limit = bb.limit(); System.out.println("Position = " + bb.position() + ", Limit = " + limit); for (int i = 0; i < limit; i++) { System.out.print(bb.get(i) + " "); } System.out.println(); } } 如果我们可以在缓冲区上使用相对get()或put()方法来读/写至少一个元素,则缓冲区的hasRemaining()方法返回true。 我们可以通过使用相对的get()或put()方法,通过使用其remaining()方法来获得我们可以读/写的最大数量的元素。...
2024-04-01