



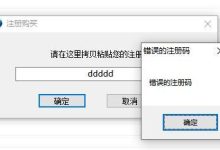
注册输入中文会报错
在当今信息技术迅猛发展的时代,各类软件和应用程序已经成为我们日常生活的重要组成部分,有些时候,我们在使用这些应用程序时,会遇到一些令人困惑的问题,比如在注册时输入中文会报错,这个问题不仅影响了用户体验,还可能让用户对应用程序的质量产生质疑,以下是对这一问题的详细分析及可能的解决方案。,我们需要明确这个问题出现的原因,通常,注册输入中文报错可能是由以下几个因素导致的:,1、编码问题:应用程序在处理中文字符时,可能没有正确地使用UTF8或其他合适的编码方式,导致系统无法识别中文字符。,2、数据库限制:有些应用的数据库在设计时可能只支持ASCII字符集,而不支持包含中文字符的Unicode字符集,这会导致在插入包含中文的数据时出现错误。,3、前端校验:前端代码可能没有正确处理中文输入,例如在表单提交前进行字符长度校验时,没有考虑到中文字符的编码长度。,4、后端处理:后端服务器在处理请求时可能没有正确处理编码转换,导致接收到的中文数据出现乱码或错误。,针对以上原因,以下是相应的解决方案:,1、确保编码正确:在开发过程中,应确保使用UTF8编码来处理中文字符,这样,无论是前端还是后端,都能正确地识别和处理中文字符。,2、修改数据库配置:对于不支持Unicode的数据库,需要修改数据库配置,使其支持Unicode字符集,对于MySQL数据库,可以修改数据库和表的字符集为utf8mb4。,3、修改前端校验逻辑:确保前端代码在处理 中文输入时,考虑到中文字符的编码长度,在JavaScript中,可以使用 String.prototype.length获取字符串的实际长度,而不是字节长度。,4、优化后端处理逻辑:后端服务器在接收请求时,应确保正确处理编码转换,在Python中,可以使用 request.encoding获取请求的编码,并在处理数据时使用 decode()和 encode()方法进行编码转换。,以下是具体的实施步骤:,1、检查前端代码,确认表单提交时是否对中文输入进行了正确的处理,检查HTML页面是否指定了UTF8编码:,2、检查前端JavaScript代码,确认是否在处理表单数据时考虑到了中文字符的编码长度:,3、修改后端代码,确保在接收请求时正确处理中文字符:,4、检查数据库配置,确保支持Unicode字符集,以MySQL为例,创建数据库和表时指定字符集:,通过以上措施,应该能够解决注册输入中文报错的问题,当然,实际开发过程中,还需要根据具体的编程语言、框架和数据库进行调整,希望以上内容能够帮助您解决这个问题,提高用户体验。, ,<meta charset=”UTF8″>,// 获取输入框的值并计算长度 var inputText = document.getElementById(“inputField”).value; var length = inputText.length;,Python示例代码 import requests from flask import Flask, request app = Flask(__name__) @app.route(‘/register’, methods=[‘POST’]) def register(): username = request.form[‘username’] # 处理中文字符 username = username.encode(‘utf8’).decode(‘utf8’) # 之后的逻辑处理,CREATE DATABASE my_database DEFAULT CHARACTER SET utf8mb4; CREATE TABLE my_table ( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(255) NOT NULL ) DEFAULT CHARACTER SET utf8mb4;,