服务器负载均衡是一种在多个服务器之间分配工作负载的技术,以提高系统性能、可靠性和可扩展性,以下是实现服务器负载均衡的详细步骤:,1、确定负载均衡需求, ,了解业务需求,确定需要多少服务器来满足预期的负载,分析系统的瓶颈,确定需要平衡哪些资源(如CPU、内存、磁盘I/O等),2、选择合适的负载均衡算法,轮询(Round Robin):按顺序将请求分配给每个服务器,适用于所有服务器性能相近的场景,加权轮询(Weighted Round Robin):根据服务器的性能为每个服务器分配权重,性能高的服务器处理更多的请求,最少连接(Least Connections):将请求分配给当前连接数最少的服务器,适用于长连接场景,IP哈希(IP Hashing):根据客户端IP地址进行哈希运算,将请求分配给特定的服务器,适用于需要会话保持的场景,其他算法:还可以选择其他负载均衡算法,如源地址哈希、URL哈希等, ,3、选择合适的负载均衡设备或软件,硬件负载均衡器:如F5、Radware等,具有较高的性能和稳定性,但成本较高,软件负载均衡器:如Nginx、HAProxy、LVS等,具有较低的成本,但性能可能略低于硬件负载均衡器,4、配置负载均衡设备或软件,根据所选的负载均衡算法和设备/软件,配置相应的参数,如服务器列表、权重、哈希键等,配置健康检查,确保只有健康的服务器才能接收请求,配置会话保持策略,如使用Cookie或源IP地址进行会话保持,5、部署和测试负载均衡环境, ,在生产环境中部署负载均衡设备或软件,确保与后端服务器正常通信,对负载均衡环境进行压力测试,验证负载均衡算法和设备/软件的性能和稳定性,6、监控和维护负载均衡环境,实时监控服务器的负载情况,以便及时调整负载均衡策略,定期检查日志,发现并解决潜在的问题,根据业务需求和技术发展,不断优化和升级负载均衡环境,实现服务器负载均衡功能可以通过硬件设备、软件算法或云服务等方式,将请求分发到多台服务器上,提高系统性能和可用性。,
Nginx(发音为“engine x”)是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器,它最初是由Igor Sysoev为俄罗斯访问量第二的Rambler.ru站点开发的,第一个公开版本0.1.0发布于2004年10月4日。,下面是关于nginx的一些基本知识:,Nginx采用了事件驱动的异步非阻塞处理模型。,在高并发连接场景下,Nginx是Apache服务不错的替代品,它具有占有内存少,稳定性高等优点。,Nginx本身做的工作一般很简单,类似于网络中间件,主要负责转发、调度请求,但Nginx能做的事情远不止这些。,正向代理:客户端发送请求到本地服务器,由本地服务器去连接后端服务器获取数据后,再返回给客户端。,反向代理:客户端发送请求到Nginx,Nginx去连接后端服务器获取数据后,再返回给客户端。, ,
在Web开发中,我们经常需要从HTML页面传递参数到后端服务器,这些参数可以是用户输入的数据、表单信息等,为了实现这一目标,我们可以使用HTTP请求(如GET或POST请求)将参数传递给服务器,在本教程中,我们将介绍如何通过SWF文件获取HTML传递进来的参数。,我们需要了解SWF文件是什么,SWF(Shockwave Flash)是一种多媒体文件格式,用于播放Adobe Flash动画和应用程序,由于安全和性能原因,Flash已经被许多现代浏览器弃用,尽管如此,我们仍然可以使用ActionScript 3.0(一种基于ECMAScript的编程语言)来创建和控制SWF文件。,要在SWF文件中获取HTML传递进来的参数,我们需要执行以下步骤:,1、在HTML页面中创建一个表单,用于收集用户输入的数据和发送请求。,在这个例子中,我们创建了一个简单的表单,包含用户名和密码字段,当用户填写表单并点击提交按钮时,表单数据将以GET请求的形式发送到名为 swf_receiver.swf的SWF文件。,2、创建一个名为 swf_receiver.as的ActionScript 3.0文件,用于接收和处理来自HTML页面的参数。,在这个例子中,我们创建了一个名为 SWFReceiver的类,该类继承自 Sprite类,我们在 init方法中处理参数,并使用 navigateToURL方法将参数传递给SWF文件,请注意,这里的URL字符串仅作为示例,实际应用中应从HTML页面获取参数值。,3、创建一个名为 swf_receiver.swf的SWF文件,用于接收和处理来自HTML页面的参数。,在这个例子中,我们创建了一个名为 swf_receiver的SWF文件,该文件继承自 Sprite类,我们在 main方法中处理参数,并使用 TextField组件显示参数值,请注意,这里的代码仅作为示例,实际应用中应根据需求进行修改。, ,<!DOCTYPE html> <html> <head> <title>传递参数给SWF文件</title> </head> <body> <form action=”swf_receiver.swf” method=”get”> <label for=”username”>用户名:</label> <input type=”text” id=”username” name=”username” required> <br> <label for=”password”>密码:</label> <input type=”password” id=”password” name=”password” required> <br> <input type=”submit” value=”提交”> </form> <script src=”swf_receiver.js”></script> </body> </html>,package { import flash.display.Sprite; import flash.events.Event; import flash.net.URLRequest; import flash.net.URLVariables; import flash.net.navigateToURL; public class SWFReceiver extends Sprite { protected function SWFReceiver():void { if (stage) init(); else addEventListener(Event.ADDED_TO_STAGE, init); } private function init(e:Event = null):void { removeEventListener(Event.ADDED_TO_STAGE, init); var urlString:String = “swf_receiver.swf?username=John&password=123456”; // 示例URL,实际应用中应从HTML页面获取参数值 var request:URLRequest = new URLRequest(urlString); navigateToURL(request, “_self”); } } },package { import flash.display.Sprite; import flash.events.Event; import flash.net.URLLoader; import flash.net.URLRequest; import flash.system.Security; import flash.text.*; import flash.utils.ByteArray; import flashx.textLayout.*; import...
三个服务器之间的IP转发设置教程,前言, ,在进行网络配置时,我们可能需要在多个服务器之间进行IP转发,本教程将指导你如何在三个服务器之间进行IP转发的设置,我们会使用Linux系统中的iptables工具来进行操作。,环境准备,确保三台服务器都已联网,并且可以互相访问。,获取每台服务器的IP地址。,登录到每台服务器的终端。,第一步:配置第一台服务器, ,1、打开终端。,2、输入以下命令来启用IP转发功能:,3、使用iptables设置转发规则,假设第一台服务器的IP地址为 192.168.1.1,第二台服务器的IP地址为 192.168.1.2,第三台服务器的IP地址为 192.168.1.3,你想要从第一台服务器转发到第二台和第三台服务器,你可以使用以下命令:,4、保存iptables规则:,第二步:配置第二台和第三台服务器,对于第二台和第三台服务器,你需要确保它们允许来自第一台服务器的流量,这通常涉及到设置防火墙规则以允许特定的流量通过,具体步骤可能会根据你的具体需求和服务器的安全策略而有所不同。, ,相关问题与解答, Q1: 我是否需要在每台服务器上重复上述步骤?,A1: 不需要,只有第一台服务器需要进行IP转发的配置,第二台和第三台服务器只需要确保它们允许来自第一台服务器的流量。, Q2: 我可以在哪些情况下使用这种IP转发设置?,A2: 当你需要将流量从一个服务器重定向到其他服务器时,这种设置非常有用,你可能有一个主服务器,它需要将请求分发到多个后端服务器,或者,你可能有一个服务器集群,需要在服务器之间进行负载均衡,在这些情况下,你可以使用IP转发来满足你的需求。,
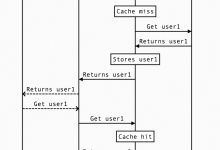
在构建需要高吞吐量和最小响应时间的系统的API时,缓存几乎是不可避免的。每个在分布式系统上工作的开发人员都曾在某个时候使用过某种缓存机制。在本文中,我们将探讨如何使用CDN构建读取缓存设计,不仅可以优化您的API,还可以降低基础架构成本。 了解一些关于缓存和CDN的知识将有助于理解本文。如果您对此一无所知,建议您先了解一些相关知识,然后再回到这里。 背景 作为后端开发人员,我们始终在努力构建高度优化的API,以为用户提供良好的体验。故事从这里开始,我们如何面对一个特定的问题,然后如何解决它。我希望您在后能够从中学到一些关于大规模系统设计的东西。 问题 我们需要开发一些API,这些API具有以下特征: 1.数据不会经常更改。2.对所有用户来说,响应是相同的,没有意外的查询参数,只是简单的GET API。3.响应数据量最多为约600 KB。4.我们预计API的吞吐量非常高(最终约为每秒5-6万次查询)。 当您第一次看到这个问题时,你的第一反应是什么?对我来说,首先想到的是,只需在节点上添加内存缓存(例如Google Guava),使用Kafka发送失效消息(因为我喜欢Kafka,它很可靠),设置服务实例的自动缩放(因为流量在一天中不均匀)。类似于下面的示意图: 1*F60S9SCN5JVmgutDCOwPKg.jpeg 嘭!问题解决了!很容易对吧?嗯,事实并非如此,像任何其他设计一样,这个设计也带来了一些缺陷。例如,对于一个简单的用例来说,这个设计略微复杂,基础架构成本将会增加,因为现在我们必须生成一个Kafka + Zookeeper集群,而且为了处理每秒5-6万次请求,我们需要水平扩展服务实例(对于我们来说是Kubernetes Pod),这意味着需要增加更多的物理节点或虚拟机。 因此,我们寻找了一种更简单和经济有效的方法,这就是我们最终开发了一种具有“使用CDN构建读取缓存”的解决方案。不久之后,我将讨论架构的细节以及权衡。 但在进一步探讨之前,让我们先了解设计的构建块。 读取缓存 标准的缓存更新策略有: 1.旁路缓存(Cache-Aside)2.读取通过缓存(Read-Through)3.写入通过缓存(Write-Through)4.写入后缓存(Write-Behind)5.提前刷新(Refresh-Ahead) 我将不详细讨论其他策略,而只关注读取缓存,因为本文只涉及此内容。让我们深入研究并了解它的工作原理。 1*CZ3W153osigEQh1u09NFNQ.png 上图很容易理解,但简要总结一下: 1.应用程序永远不直接与数据库交互,而始终通过缓存进行。2.在缓存未命中时,缓存将从数据库中读取数据并丰富缓存存储。3.在缓存命中时,数据将从缓存中提供。 您可以看到,数据库很少被频繁访问,响应速度很快,因为缓存主要是内存中的(如Redis或Memcached)。已经解决了很多问题。 CDN 互联网上关于CDN的定义是:“内容传递网络(CDN)是一种全球分布的代理服务器网络,用于在离用户更近的位置提供内容,并用于提供静态文件,如图像、视频、HTML、CSS文件”。但我们将违反潮流,使用CDN提供动态内容(JSON响应,而不是JSON文件)。 此外,从概念上说,通常有两种CDN: 1.推送CDN(Push CDN):您负责将数据上传到CDN服务器。2.拉取CDN(Pull CDN):CDN将从您的服务器(源服务器)拉取数据。 我们将使用拉取CDN,因为使用推送方法,我必须处理重试、幂等性和其他内容,这对我来说是一个额外的麻烦,而且对于这个用例并没有真 正添加任何价值。 将CDN作为读取缓存 这个想法很简单,我们将CDN作为用户和实际后端服务之间的缓存层。如下图所示: 1*fn-zmPouY7r3XoWS5c-mzQ.jpeg 正如您所看到的,CDN位于客户端和我们的后端服务之间,并成为缓存。数据流顺序如下: 1*4oGxf26V7E7MYAGKl4MtnA.png 让我们深入探讨一下,因为这是设计的精髓。 用于缩写的缩写 ?T1 -> 时间实例1 + 毫秒数?T2 -> 时间实例1 + 1分钟+某些毫秒数?TTL -> 存活时间?源服务器 -> 您实际的后端服务 1.T1:客户端请求获取user1。2.T1:请求着陆在CDN上。3.T1:CDN发现在其缓存存储中没有user1相关的键。4.T1:CDN到上游,即实际的后端服务,以获取user1。5.T1:后端服务返回user1作为标准的JSON响应。6.T1:CDN接收到JSON,现在它需要存储它。7.所以现在需要决定这个数据的TTL,它是如何做到的?8.通常有两种设置TTL的方式,要么源服务器指定数据应该被缓存多长时间,要么在CDN配置中设置了一个恒定值,它使用该时间来设置TTL。9.最好让源服务器控制TTL,这样我们有能力根据需要控制TTL或具有条件的TTL。10.那么问题就产生了,源服务器如何指定TTL。缓存控制头(Cache-Control headers)来拯救。来自源服务器的响应可以包含像 cache-control: public, max-age: 180 这样的缓存控制头。这将转化为该数据可以被公开缓存,有效期为180秒。11.T1:现在CDN看到这一点并使用180秒的TTL缓存了数据。12.T1:CDN向调用者响应user1 JSON。13.T2:另一个客户端请求user1。14.T2:请求着陆在CDN上。15.T2:CDN看到它的缓存中有user1键,因此不会到源服务器,而是返回缓存的JSON响应。16.T3:CDN在180秒后缓存失效。17.T4:某个客户端请求user1,但由于缓存为空,流程再次从第3步开始。这种情况一直重复。 不一定要将TTL设置为180秒。选择TTL是根据您能够提供过期数据多长时间以及是否接受它而选择的。如果这引发了一个问题,为什么不能在数据更改时使缓存失效,那么请稍等,我马上在缺点部分回答。 实施 1*vrlRYFpBKKy5IqDSbrUidA.jpeg 请求合并 但还有一个问题,CDN承担了所有负载,我们不必进行扩展。但我们的吞吐量达到了每秒60,000次查询,这意味着在缓存未命中的情况下,会有60,000个请求同时命中我们的源服务(假设需要1秒来填充CDN缓存),这可能会使服务不堪重负。 这就是请求合并的工作方式: 1*ze0WtYQVhFRtClZq0GEoVQ.jpeg 顾名思义,它基本上将具有相同查询参数的多个请求合并在一起,并将很少的请求发送到源服务器。 我们设计的美妙之处在于,我们不必自己执行请求合并,CDN将帮助我们执行。正如我已经提到的,我们使用的是Google Cloud CDN,它有请求合并的概念,这只是请求合并的另一种名称。因此,当在同一时间进行大量的缓存填充请求时,CDN会识别出这一点,每个CDN节点只发送一个请求到源服务器,然后从该响应中响应所有这些请求。这就是如何保护我们的源服务器免受高流量的影响。 好的,我们现在接近结束了,任何设计在没有经过利弊分析之前都是不完整的。因此,让我们稍微分析一下这个设计,看看它如何有所帮助,以及它的不足之处。 设计的优点 1.简单性: 这个设计非常简单,易于实现和维护。2.响应时间: 您已经知道CDN服务器的地理位置优化了数据传输,因此我们的响应时间也变得非常快。例如,忽略TCP连接建立时间,60毫秒听起来如何?3.减少负载: 由于实际的后端服务器现在只收到约每180秒1个请求,负载非常低。 设计的缺点 1.缓存失效: 缓存失效是计算机科学中最难正确执行的事情之一,而且由于CDN成为缓存,它变得更加困难。在CDN上的任意即兴的缓存失效是一个昂贵的过程,通常不会实时发生。如果数据发生更改,由于我们无法使CDN上的缓存失效,您的客户端可能会在一段时间内获得旧数据。但这又取决于您设置的TTL,如果TTL为几小时,那么您也可以在CDN上调用缓存失效。但如果TTL以秒/分钟为单位,这可能会有问题。此外,请记住,并非所有CDN提供商都提供API以使CDN缓存失效。2.控制较少: 由于请求现在不会着陆在我们的服务器上,因此会有这样一种感觉,即作为开发人员,您对系统没有足够的控制。可观察性可能会受到轻微影响,您可以在CDN上设置日志记录和监控,但这通常会带来一定的成本。 最后 在分布式世界中的任何设计都具有一定程度的主观性,并且总会有一些权衡。作为开发人员/架构师,我们的职责是权衡各种权衡,并选择适合我们的设计。说到这里,没有哪种设计足够具体以继续下去,因此鉴于约束条件,我们选择了一种设计,根据它的运作方式,我们可能会进一步演化它。
,