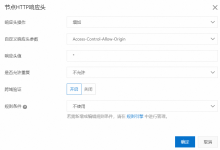
前言 今天在设置网站时,有一个资源显示Access-Control-Allow-Origin这个跨域错误,但是图片又是正常使用的,查了下文档也是解决了的,就想着写一篇文章记录一下,相信大家也是会遇到这个问题的。 为什么出现这个问题 首先了解一下,什么是跨域:跨域资源共享CORS(Cross-Origin Resource Sharing)简称跨域访问,是HTML5提供的标准跨域解决方案,允许网页从不同源加载和访问跨域资源,使得跨域数据传输得以安全进行 由于安全限制,浏览器一般会遵循同源策略(Same-Origin Policy),限制网页发起从不同域、子域、协议或端口加载和访问资源的请求,例如example.com无法访问example.org上的资源。通过配置跨域资源共享,可以在CDN服务器端设置相关的响应头,如果访问CDN资源时的请求携带了满足允许规则内的请求头,即可实现跨域资源的加载和访问。 以阿里云为例 登录CDN控制台。 在左侧导航栏,单击域名管理。 在域名管理页面,找到目标域名,单击操作列的管理。 在指定域名的左侧导航栏,单击缓存配置。 单击节点HTTP响应头页签。 单击添加,配置节点HTTP响应头。 请按照以下内容进行选择,设置指定允许的跨域请求的来源,然后单击确定保存配置。 配置示例 如果跨域资源共享的响应头值设置了单个或者多个值(多个值之间用“,”分隔)。 如果用户请求头里携带的“Origin”参数值与被设置的任意一个值精确匹配,就会响应对应的跨域头。 如果都没有精确匹配上,则不响应跨域头。 CDN上设置:Access-Control-Allow-Origin:http://example.com,https://aliyundoc.com。 如果用户请求携带的Origin头是http://example.com,则CDN节点将会响应Access-Control-Allow-Origin:http://example.com。 如果用户请求携带的Origin头是http://aliyundoc.com,则CDN节点将不会响应Access-Control-Allow-Origin(协议头不匹配,用户请求的是HTTP协议,CDN上设置的是HTTPS协议)。 如果用户请求携带的Origin头是https://aliyundoc.com,则CDN节点将会响应Access-Control-Allow-Origin:https://aliyundoc.com。 如果用户请求携带的Origin头是http://aliyun.com,则CDN节点将不会响应Access-Control-Allow-Origin(域名不匹配)。 本文作者:微信公众号:花摇响铃铛
CDN(内容分发网络)通常提供了自定义规则与策略的功能,让用户可以根据自己的需求和情况对流量进行更精细化的控制和管理。以下是一些常见的CDN自定义规则与策略: 缓存规则:用户可以根据自己的需求定义缓存规则,包括缓存时间、缓存内容、缓存位置等。这样可以根据网站的特点和用户访问模式,灵活控制缓存策略,提高网站的访问速度和性能。 访问控制列表(ACL):ACL允许用户定义特定的访问控制规则,例如允许或拒绝特定IP地址、地理位置、User-Agent等的访问。这可以帮助用户实现对敏感内容的访问控制,提高网站的安全性。 URL重写:用户可以使用URL重写功能,对请求的URL进行重写或者重定向。这可以帮助用户实现URL的美化、网站结构调整、SEO优化等目的。 响应头控制:用户可以通过设置响应头来控制服务器返回给客户端的HTTP响应头信息,例如设置缓存控制、CORS策略、内容类型等。这有助于优化网站性能和安全性。 防盗链:防盗链功能允许用户限制只有特定来源(referrer)的请求才能访问网站资源,防止资源被恶意盗用。用户可以设置允许的来源列表或者自定义拒绝访问策略。 加密与解密:CDN可以提供加密与解密功能,帮助用户对传输的数据进行加密保护,防止数据被窃听或篡改。用户可以选择使用HTTPS协议或者其他加密方式来保护数据安全。 流量分发策略:用户可以定义流量分发策略,例如基于地理位置、网络运营商、服务器负载等因素进行流量分发和负载均衡。这有助于优化网站的访问速度和稳定性。 自定义缓存刷新:用户可以手动或者自动触发缓存刷新操作,例如根据文件修改时间、URL变化、特定事件触发等条件来刷新缓存内容,确保网站内容的及时更新。 这些自定义规则与策略可以帮助用户更好地控制和管理CDN服务,提高网站的性能、安全性和可用性。具体的实现方式和操作方法可能因CDN服务提供商而异,用户可以根据自己的需求选择合适的CDN服务并进行相应的配置和管理。
HTML(HyperText Markup Language,超文本标记语言)本身不包含特定的编码格式信息,因为它只是一种用于创建网页结构的标记语言,不过,网页的编码格式通常是由其头部的元数据(metadata)中定义的,或者通过HTTP响应头中的 ContentType字段来指定。,要查看HTML文档的编码格式,你可以通过以下几种方法:,1、查看HTML文件的元数据( <meta>标签):,在HTML文档的 <head>部分,通常会有一个 <meta>标签用来声明文档的字符编码。,“`html,<meta charset=”UTF8″>,“`,如果你在浏览器中打开一个页面,并想查看这个信息,你可以右击页面选择“查看页面源代码”或“检查元素”(Inspect Element),然后在打开的代码视图中搜索 charset属性。,2、查看HTTP响应头:,当你通过浏览器访问一个网页时,浏览器会发送一个HTTP请求,然后服务器会返回一个HTTP响应,其中包含了许多信息,包括 ContentType字段,它定义了文档的MIME类型和字符编码。,你可以通过开发者工具的网络(Network)面板来查看这些信息,以下是步骤:,打开你想要检查的网页。,右键点击页面,选择“检查”(Inspect),打开开发者工具。,转到“网络”(Network)标签。,刷新页面,让开发者工具捕获加载过程中的信息。,在“网络”面板中找到主HTML文档的条目,点击它。,查看响应头(Response Headers)部分,寻找 ContentType字段。,如果该字段包含 charset参数,那么它的值就是文档的字符编码。,“`,ContentType: text/html; charset=utf8,“`,3、使用在线工具和服务:,有一些在线服务和工具可以帮助你检测网页的编码,你可以使用 W3C Markup Validation Service来检测HTML代码是否符合标准,并获取编码信息。,4、使用编程语言检测:,如果你想通过编程的方式检测HTML文档的编码,可以使用各种库和函数来实现,比如在Python中,你可以使用 beautifulsoup4或 chardet库来检测编码。,5、注意默认编码:,如果你没有找到明确的编码声明,浏览器通常会使用一些默认的编码来解析网页,HTML5规范默认推荐使用UTF8编码。,确定HTML文档的编码格式通常首先检查 meta标签中的 charset声明,其次查看HTTP响应头的 ContentType字段,如果这两种方式都无法确定,可能需要依赖其他工具或手段进行检测,在现代Web开发实践中,明确声明编码格式是一种好的做法,这样可以避免因字符编码不一致而导致的内容显示问题。, ,