共 2 篇文章
标签:word绘制表格怎么能画一条线呢

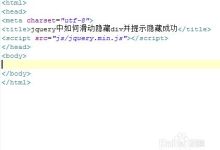
在网页开发中,我们经常需要控制HTML元素的显示和隐藏,jQuery是一个流行的JavaScript库,它提供了一种简洁的方式来操作DOM元素,包括显示和隐藏元素,在本教程中,我们将学习如何使用jQuery来控制div元素的显示和隐藏。,1、引入jQuery库,我们需要在HTML文件中引入jQuery库,你可以通过以下方式之一来引入:,方法一:使用 <script>标签直接引入,方法二:通过 CDN引入,2、编写HTML结构,接下来,我们需要编写一个简单的HTML结构,包含一个div元素,以及一些按钮用于控制div的显示和隐藏。,3、编写jQuery代码,现在我们可以编写jQuery代码来控制div的显示和隐藏,我们需要为“显示”和“隐藏”按钮添加点击事件监听器,在事件处理函数中,我们可以使用jQuery的 toggle()方法来切换div的显示和隐藏状态,我们需要将jQuery代码放入 <script>标签中。,4、测试效果,保存HTML文件,然后在浏览器中打开它,点击“显示”按钮,你应该可以看到蓝色的div元素,再次点击“显示”按钮,div元素应该消失,点击“隐藏”按钮,div元素应该重新出现,这表明我们已经成功地使用jQuery控制了div元素的显示和隐藏。,在本教程中,我们学习了如何使用jQuery来控制div元素的显示和隐藏,我们首先引入了jQuery库,然后编写了一个简单的HTML结构,包含一个div元素和两个按钮,接着,我们编写了jQuery代码,为按钮添加了点击事件监听器,并使用 toggle()方法来切换div的显示和隐藏状态,我们测试了效果,确保一切正常,希望本教程对你有所帮助!,
获取网页的HTML文件,通常可以通过两种方式:一种是手动复制粘贴,另一种是通过编程方式,这里我们主要介绍通过编程方式来获取网页的HTML文件。,在Python中,我们可以使用requests库和BeautifulSoup库来实现这个功能,requests库用于发送HTTP请求,获取网页的HTML内容;BeautifulSoup库用于解析HTML内容,提取我们需要的信息。,以下是具体的步骤:,1、安装requests和BeautifulSoup库,在命令行中输入以下命令:,2、导入requests和BeautifulSoup库,在Python代码中输入以下命令:,3、发送HTTP请求,获取网页的HTML内容,在Python代码中输入以下命令:,4、解析HTML内容,提取我们需要的信息,在Python代码中输入以下命令:,以上就是通过编程方式获取网页HTML文件的基本步骤,需要注意的是,不同的网页可能有不同的结构,因此在实际使用时,可能需要根据具体的网页结构来修改代码。,如果网页使用了动态加载技术(例如Ajax),那么直接发送HTTP请求可能无法获取到完整的HTML内容,在这种情况下,我们可能需要使用更复杂的工具,例如Selenium或Scrapy等。,Selenium是一个自动化测试工具,可以模拟用户操作浏览器,从而获取动态加载的内容,Scrapy是一个强大的爬虫框架,可以处理各种复杂的网页结构和反爬机制,这两个工具的使用都比较复杂,需要一定的编程基础和网络知识,如果你对这些工具感兴趣,可以查阅相关的教程和文档,深入学习和实践。,获取网页的HTML文件是一项非常实用的技能,可以帮助我们快速获取和分析网络信息,通过学习和实践,我们可以掌握这项技能,提高我们的工作效率和学习效果。,,pip install requests beautifulsoup4,import requests from bs4 import BeautifulSoup,url = ‘https://www.bilibili.com’ # 这里替换为你想要获取HTML内容的网页URL response = requests.get(url) html_content = response.text # 获取网页的HTML内容,soup = BeautifulSoup(html_content, ‘html.parser’) # 使用BeautifulSoup解析HTML内容 这里可以添加你需要提取的信息,例如提取所有的标题 titles = soup.find_all(‘h1’) # 查找所有的h1标签,即所有的标题 for title in titles: print(title.text) # 打印每个标题的文本内容,