在Web开发中,我们经常需要从HTML页面中提取内容,这可能是因为我们需要分析网页结构,或者将网页内容导入到其他应用程序中,有多种方法可以调用HTML页面内容,以下是一些常用的技术:,1、使用Python的requests库和BeautifulSoup库,requests库是一个用于发送HTTP请求的Python库,而BeautifulSoup库是一个用于解析HTML和XML文档的Python库,通过这两个库,我们可以很容易地从HTML页面中提取所需的内容。,确保已经安装了requests和BeautifulSoup库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的Python脚本来调用HTML页面内容:,2、使用JavaScript的Fetch API和DOM操作,Fetch API是一个现代的JavaScript函数,用于发送HTTP请求并获取响应,通过结合DOM操作,我们可以在浏览器端轻松地调用HTML页面内容。,以下是一个使用Fetch API和DOM操作的JavaScript示例:,3、使用Java的Jsoup库,Jsoup是一个用于处理实际世界HTML的Java库,它提供了非常方便的API来提取和操作数据,以及清理用户提交的内容,通过Jsoup,我们可以在Java应用程序中轻松地调用HTML页面内容。,确保已经安装了Jsoup库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的Java程序来调用HTML页面内容:,4、使用PHP的cURL库和DOMDocument类,cURL是一个强大的工具,可以用来获取或发送数据,包括HTTP、HTTPS等协议,通过结合DOMDocument类,我们可以在PHP应用程序中轻松地调用HTML页面内容。,确保已经安装了cURL库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的PHP程序来调用HTML页面内容:,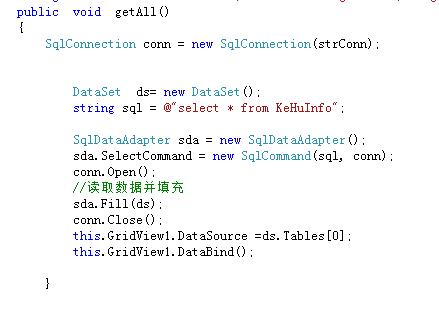
,pip install requests pip install beautifulsoup4,import requests from bs4 import BeautifulSoup 发送HTTP请求并获取HTML内容 url = ‘https://www.example.com’ response = requests.get(url) html_content = response.text 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(html_content, ‘html.parser’) 提取所需内容,例如提取所有的段落标签<p> paragraphs = soup.find_all(‘p’) for p in paragraphs: print(p.text),// 发送HTTP请求并获取HTML内容 fetch(‘https://www.example.com’) .then(response => response.text()) .then(html_content => { // 使用DOM操作提取所需内容,例如提取所有的段落标签<p> const paragraphs = document.querySelectorAll(‘p’); paragraphs.forEach(p => { console.log(p.textContent); }); });,mvn dependency:get DgroupId=org.jsoup DartifactId=jsoup Dversion=1.14.3,import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Main { public static void main(String[] args) { try { // 发送HTTP请求并获取HTML内容 Document doc = Jsoup.connect(“https://www.example.com”).get(); // 提取所需内容,例如提取所有的段落标签<p> Elements paragraphs = doc.select(“p”); for (Element p : paragraphs) { System.out.println(p.text()); } } catch (IOException e) { e.printStackTrace(); } } }
如何调用html页面内容
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《如何调用html页面内容》
文章链接:https://zhuji.vsping.com/330611.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《如何调用html页面内容》
文章链接:https://zhuji.vsping.com/330611.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。