C++教程 第3页 常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。 常量可以是任何的基本数据类型,可分为整型数字、浮点数字、字符、字符串和布尔值。 常量就像是常规的变量,只不过常量的值在定义后不能进行修改。 整数常量 整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。 整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。 下面列举几个整数常量的实例: 212 // 合法的 215u // 合法的 0xFeeL // 合法的 078 // 非法的:8 不是八进制的数字 032UU // 非法的:不能重复后缀 以下是各种类型的整数常量的实例: 85 // 十进制 0213 // 八进制 0x4b // 十六进制 30 // 整数 30u // 无符号整数 30l // 长整数 30ul // 无符号长整数 浮点常量 浮点常量由整数部分、小数点、小数部分和指数部分组成。您可以使用小数形式或者指数形式来表示浮点常量。 当使用小数形式表示时,必须包含小数点、指数,或同时包含两者。当使用指数形式表示时,必须包含整数部分、小数部分,或同时包含两者。带符号的指数是用 e 或 E 引入的。 下面列举几个浮点常量的实例: 3.14159 // 合法的 314159E-5L // 合法的 510E // 非法的:不完整的指数 210f // 非法的:没有小数或指数 .e55 // 非法的:缺少整数或分数 布尔常量 布尔常量共有两个,它们都是标准的 C++ 关键字: true 值代表真。 false 值代表假。 我们不应把 true 的值看成 1,把 false 的值看成 0。 字符常量 字符常量是括在单引号中。如果常量以 L(仅当大写时)开头,则表示它是一个宽字符常量(例如 L’x’),此时它必须存储在 wchar_t 类型的变量中。否则,它就是一个窄字符常量(例如 ‘x’),此时它可以存储在 char 类型的简单变量中。 字符常量可以是一个普通的字符(例如 ‘x’)、一个转义序列(例如 ‘\t’),或一个通用的字符(例如 ‘\u02C0’)。 在 C++ 中,有一些特定的字符,当它们前面有反斜杠时,它们就具有特殊的含义,被用来表示如换行符(\n)或制表符(\t)等。下表列出了一些这样的转义序列码: 转义序列 含义 \\ \ 字符 \’ ‘ 字符...
2024-04-04
作用域是程序的一个区域,一般来说有三个地方可以声明变量: 在函数或一个代码块内部声明的变量,称为局部变量。 在函数参数的定义中声明的变量,称为形式参数。 在所有函数外部声明的变量,称为全局变量。 我们将在后续的章节中学习什么是函数和参数。本章我们先来讲解声明是局部变量和全局变量。 局部变量 在函数或一个代码块内部声明的变量,称为局部变量。它们只能被函数内部或者代码块内部的语句使用。下面的实例使用了局部变量: #include <iostream> using namespace std; int main () { // 局部变量声明 int a, b; int c; // 实际初始化 a = 10; b = 20; c = a + b; cout << c; return 0; } 尝试一下 全局变量 在所有函数外部定义的变量(通常是在程序的头部),称为全局变量。全局变量的值在程序的整个生命周期内都是有效的。 全局变量可以被任何函数访问。也就是说,全局变量一旦声明,在整个程序中都是可用的。下面的实例使用了全局变量和局部变量: #include <iostream> using namespace std; // 全局变量声明 int g; int main () { // 局部变量声明 int a, b; // 实际初始化 a = 10; b = 20; g = a + b; cout << g; return 0; } 尝试一下 在程序中,局部变量和全局变量的名称可以相同,但是在函数内,局部变量的值会覆盖全局变量的值。下面是一个实例: #include <iostream> using namespace std; // 全局变量声明 int g = 20; int main () { // 局部变量声明 int g = 10; cout << g; return 0; } 尝试一下 当上面的代码被编译和执行时,它会产生下列结果: 10 初始化局部变量和全局变量 当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动初始化为下列值: 数据类型 初始化默认值 int 0 char ‘\0’ float 0 double 0 pointer NULL 正确地初始化变量是一个良好的编程习惯,否则有时候程序可能会产生意想不到的结果。
2024-04-04
使用编程语言进行编程时,需要用到各种变量来存储各种信息。变量保留的是它所存储的值的内存位置。这意味着,当您创建一个变量时,就会在内存中保留一些空间。 您可能需要存储各种数据类型(比如字符型、宽字符型、整型、浮点型、双浮点型、布尔型等)的信息,操作系统会根据变量的数据类型,来分配内存和决定在保留内存中存储什么。 基本的内置类型 C++ 为程序员提供了种类丰富的内置数据类型和用户自定义的数据类型。下表列出了七种基本的 C++ 数据类型: 类型 关键字 布尔型 bool 字符型 char 整型 int 浮点型 float 双浮点型 double 无类型 void 宽字符型 wchar_t 一些基本类型可以使用一个或多个类型修饰符进行修饰: signed unsigned short long 下表显示了各种变量类型在内存中存储值时需要占用的内存,以及该类型的变量所能存储的最大值和最小值。 注意:不同系统会有所差异。 类型 位 范围 char 1 个字节 -128 到 127 或者 0 到 255 unsigned char 1 个字节 0 到 255 signed char 1 个字节 -128 到 127 int 4 个字节 -2147483648 到 2147483647 unsigned int 4 个字节 0 到 4294967295 signed int 4 个字节 -2147483648 到 2147483647 short int 2 个字节 -32768 到 32767 unsigned short int 2 个字节 0 到 65,535 signed short int 2 个字节 -32768 到 32767 long int 8 个字节 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 signed long int 8 个字节 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 unsigned long int 8 个字节...
2024-04-04
提供基本语法和方法的 C++ 快速参考备忘单。 开始 Hello.cpp #include <iostream> int main() { std::cout << "Hello QuickRef\n"; return 0; } 编译和运行 $ g++ hello.cpp -o hello $ ./hello Hello QuickRef 变量 int number = 5; // Integer float f = 0.95; // Floating number double PI = 3.14159; // Floating number char yes = 'Y'; // Character std::string s = "ME"; // String (text) bool isRight = true; // Boolean // Constants const float RATE = 0.8; int age {25}; // Since C++11 std::cout << age; // Print 25 原始数据类型 数据类型 尺寸 范围 int 4字节 -2 31 ~ 2 31 -1 float 4字节 不适用 double 8 字节 不适用 char 1 字节 -128 ~ 127 bool 1 字节 true / false void 不适用 不适用 wchar_t 2 或 4...
2024-04-04
在 C++ 中,vector 是一个十分有用的容器。它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。 C++ 中数组很坑,有没有类似 Python 中 list 的数据类型呢?类似的就是 vector!vector 是同一种类型的对象的集合,每个对象都有一个对应的整数索引值。和 string 对象一样,标准库将负责管理与存储元素相关的内存。我们把 vector 称为容器,是因为它可以包含其他对象。一个容器中的所有对象都必须是同一种类型的。 一、什么是vector? 向量(vector)是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。 二、容器特性 1.顺序序列 顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。 2.动态数组 支持对序列中的任意元素进行快速直接访问,甚至可以通过指针算述进行该操作。操供了在序列末尾相对快速地添加/删除元素的操作。 3.能够感知内存分配器的(Allocator-aware) 容器使用一个内存分配器对象来动态地处理它的存储需求。 三、基本函数实现 1.构造函数 vector():创建一个空vector vector(int nSize):创建一个vector,元素个数为nSize vector(int nSize,const t& t):创建一个vector,元素个数为nSize,且值均为t vector(const vector&):复制构造函数 vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中 2.增加函数 void push_back(const T& x):向量尾部增加一个元素X iterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一个元素x iterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n个相同的元素x iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据 3.删除函数 iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素 void pop_back():删除向量中最后一个元素 void clear():清空向量中所有元素 4.遍历函数 reference at(int pos):返回pos位置元素的引用 reference front():返回首元素的引用 reference back():返回尾元素的引用 iterator begin():返回向量头指针,指向第一个元素 iterator end():返回向量尾指针,指向向量最后一个元素的下一个位置 reverse_iterator rbegin():反向迭代器,指向最后一个元素 reverse_iterator rend():反向迭代器,指向第一个元素之前的位置 5.判断函数 bool empty() const:判断向量是否为空,若为空,则向量中无元素 6.大小函数 int size() const:返回向量中元素的个数 int capacity() const:返回当前向量所能容纳的最大元素值 int max_size() const:返回最大可允许的 vector 元素数量值 7.其他函数 void swap(vector&):交换两个同类型向量的数据 void assign(int n,const T& x):设置向量中前n个元素的值为x void assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素 8.看着清楚 push_back 在数组的最后添加一个数据 pop_back 去掉数组的最后一个数据 at 得到编号位置的数据 begin 得到数组头的指针 end 得到数组的最后一个单元+1的指针 front 得到数组头的引用 back 得到数组的最后一个单元的引用 max_size 得到vector最大可以是多大 capacity 当前vector分配的大小...
2024-04-04
C++ STL 教程 在前面的章节中,我们已经学习了 C++ 模板的概念。C++ STL(标准模板库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法和数据结构,如向量、链表、队列、栈。 C++ 标准模板库的核心包括以下三个组件: 组件 描述 容器(Containers) 容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。 算法(Algorithms) 算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。 迭代器(iterators) 迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。 这三个组件都带有丰富的预定义函数,帮助我们通过简单的方式处理复杂的任务。 下面的程序演示了向量容器(一个 C++ 标准的模板),它与数组十分相似,唯一不同的是,向量在需要扩展大小的时候,会自动处理它自己的存储需求: #include <iostream> #include <vector> using namespace std; int main() { // 创建一个向量存储 int vector<int> vec; int i; // 显示 vec 的原始大小 cout << "vector size = " << vec.size() << endl; // 推入 5 个值到向量中 for(i = 0; i < 5; i++){ vec.push_back(i); } // 显示 vec 扩展后的大小 cout << "extended vector size = " << vec.size() << endl; // 访问向量中的 5 个值 for(i = 0; i < 5; i++){ cout << "value of vec [" << i << "] = " << vec[i] << endl; } // 使用迭代器 iterator 访问值 vector<int>::iterator v =...
2024-04-04
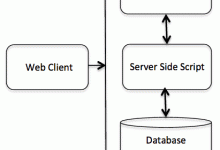
C++ Web 编程 什么是 CGI? 公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的。 CGI 规范目前是由 NCSA 维护的,NCSA 定义 CGI 如下: 公共网关接口(CGI),是一种用于外部网关程序与信息服务器(如 HTTP 服务器)对接的接口标准。 目前的版本是 CGI/1.1,CGI/1.2 版本正在推进中。 Web 浏览 为了更好地了解 CGI 的概念,让我们点击一个超链接,浏览一个特定的网页或 URL,看看会发生什么。 您的浏览器联系上 HTTP Web 服务器,并请求 URL,即文件名。 Web 服务器将解析 URL,并查找文件名。如果找到请求的文件,Web 服务器会把文件发送回浏览器,否则发送一条错误消息,表明您请求了一个错误的文件。 Web 浏览器从 Web 服务器获取响应,并根据接收到的响应来显示文件或错误消息。 然而,以这种方式搭建起来的 HTTP 服务器,不管何时请求目录中的某个文件,HTTP 服务器发送回来的不是该文件,而是以程序形式执行,并把执行产生的输出发送回浏览器显示出来。 公共网关接口(CGI),是使得应用程序(称为 CGI 程序或 CGI 脚本)能够与 Web 服务器以及客户端进行交互的标准协议。这些 CGI 程序可以用 Python、PERL、Shell、C 或 C++ 等进行编写。 CGI 架构图 下图演示了 CGI 的架构: Web 服务器配置 在您进行 CGI 编程之前,请确保您的 Web 服务器支持 CGI,并已配置成可以处理 CGI 程序。所有由 HTTP 服务器执行的 CGI 程序,都必须在预配置的目录中。该目录称为 CGI 目录,按照惯例命名为 /var/www/cgi-bin。虽然 CGI 文件是 C++ 可执行文件,但是按照惯例它的扩展名是 .cgi。 默认情况下,Apache Web 服务器会配置在 /var/www/cgi-bin 中运行 CGI 程序。如果您想指定其他目录来运行 CGI 脚本,您可以在 httpd.conf 文件中修改以下部分: <Directory "/var/www/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> <Directory "/var/www/cgi-bin"> Options All </Directory> 在这里,我们假设已经配置好 Web 服务器并能成功运行,你可以运行任意的 CGI 程序,比如 Perl 或 Shell...
2024-04-04
C++ 信号处理 信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 Ctrl+C 产生中断。 有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作。这些信号是定义在 C++ 头文件 <csignal> 中。 信号 描述 SIGABRT 程序的异常终止,如调用 abort。 SIGFPE 错误的算术运算,比如除以零或导致溢出的操作。 SIGILL 检测非法指令。 SIGINT 接收到交互注意信号。 SIGSEGV 非法访问内存。 SIGTERM 发送到程序的终止请求。 signal() 函数 C++ 信号处理库提供了 signal 函数,用来捕获突发事件。以下是 signal() 函数的语法: void (*signal (int sig, void (*func)(int)))(int); 这个函数接收两个参数:第一个参数是一个整数,代表了信号的编号;第二个参数是一个指向信号处理函数的指针。 让我们编写一个简单的 C++ 程序,使用 signal() 函数捕获 SIGINT 信号。不管您想在程序中捕获什么信号,您都必须使用 signal 函数来注册信号,并将其与信号处理程序相关联。看看下面的实例: #include <iostream> #include <csignal> #include <unistd.h> using namespace std; void signalHandler( int signum ) { cout << "Interrupt signal (" << signum << ") received.\n"; // 清理并关闭 // 终止程序 exit(signum); } int main () { // 注册信号 SIGINT 和信号处理程序 signal(SIGINT, signalHandler); while(1){ cout << "Going to sleep...." << endl; sleep(1); } return 0; } 当上面的代码被编译和执行时,它会产生下列结果: Going to sleep.... Going to sleep.... Going to sleep.... 现在,按...
2024-04-04
C++ 预处理器 预处理器是一些指令,指示编译器在实际编译之前所需完成的预处理。 所有的预处理器指令都是以井号(#)开头,只有空格字符可以出现在预处理指令之前。预处理指令不是 C++ 语句,所以它们不会以分号(;)结尾。 我们已经看到,之前所有的实例中都有 #include 指令。这个宏用于把头文件包含到源文件中。 C++ 还支持很多预处理指令,比如 #include、#define、#if、#else、#line 等,让我们一起看看这些重要指令。 #define 预处理 #define 预处理指令用于创建符号常量。该符号常量通常称为宏,指令的一般形式是: #define macro-name replacement-text 当这一行代码出现在一个文件中时,在该文件中后续出现的所有宏都将会在程序编译之前被替换为 replacement-text。例如: #include <iostream> using namespace std; #define PI 3.14159 int main () { cout << "Value of PI :" << PI << endl; return 0; } 现在,让我们测试这段代码,看看预处理的结果。假设源代码文件已经存在,接下来使用 -E 选项进行编译,并把结果重定向到 test.p。现在,如果您查看 test.p 文件,将会看到它已经包含大量的信息,而且在文件底部的值被改为如下: $gcc -E test.cpp > test.p ... int main () { cout << "Value of PI :" << 3.14159 << endl; return 0; } 函数宏 您可以使用 #define 来定义一个带有参数的宏,如下所示: #include <iostream> using namespace std; #define MIN(a,b) (((a)<(b)) ? a : b) int main () { int i, j; i = 100; j = 30; cout <<"The minimum is " << MIN(i, j) << endl; return 0; } 当上面的代码被编译和执行时,它会产生下列结果: The...
2024-04-04
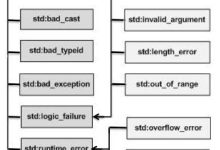
C++ 异常处理 异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。 异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。 throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。 catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。 try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。 如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示: try { // 保护代码 }catch( ExceptionName e1 ) { // catch 块 }catch( ExceptionName e2 ) { // catch 块 }catch( ExceptionName eN ) { // catch 块 } 如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。 抛出异常 您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。 以下是尝试除以零时抛出异常的实例: double division(int a, int b) { if( b == 0 ) { throw "Division by zero condition!"; } return (a/b); } 捕获异常 catch 块跟在 try 块后面,用于捕获异常。您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。 try { // 保护代码 }catch( ExceptionName e ) { // 处理 ExceptionName 异常的代码 } 上面的代码会捕获一个类型为 ExceptionName 的异常。如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 …,如下所示: try { //...
2024-04-04