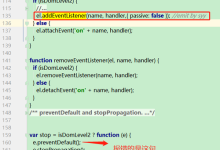
在JavaScript开发中,遇到报错是常有的事情,报错是帮助我们识别代码中潜在问题的一种机制,理解并解决这些报错是提高代码质量的重要步骤,下面我将详细描述一些常见的JavaScript报错类型,以及对应的解决方法。,语法错误(SyntaxError),这是最常见的错误类型,通常是由于代码不符合JavaScript语法规则造成的。, 示例:, 错误信息:, 解决方法:,检查是否有遗漏的括号、引号或者分号等。,确保使用的变量和函数名称符合JavaScript的标识符规则。,使用代码编辑器的语法检查功能,通常它们能高亮显示错误的代码。,类型错误(TypeError),当变量或值不是预期类型时,会发生类型错误。, 示例:, 错误信息:, 解决方法:,确保调用的方法或属性存在于相应的对象上。,使用 typeof和 instanceof操作符检查变量类型。,对变量进行适当的类型转换。,引用错误(ReferenceError),引用错误通常发生在尝试访问一个未定义的变量时。, 示例:, 错误信息:, 解决方法:,确保变量在使用前已经被声明和赋值。,检查是否有拼写错误或者大小写不匹配的情况。,查看变量作用域,确保在正确的范围内访问变量。,RangeError,当值超出有效范围时,会发生此错误。, 示例:, 错误信息:, 解决方法:,检查函数或方法调用时的参数是否在允许的范围内。,对于数组长度、循环迭代次数等,确保它们为非负整数。,URIError,当全局URI处理函数被错误使用时触发。, 示例:, 错误信息:, 解决方法:,确保传递给URI处理函数的字符串格式正确。,对可能引起问题的输入进行验证。,解决步骤,1、 阅读错误信息: 错误信息通常会给出发生错误的位置和原因,这是解决问题的第一步。,2、 审查代码: 根据错误信息,审查发生错误的那部分代码,查看是否有明显的错误。,3、 逐行调试: 使用 console.log输出调试信息,或者使用开发者工具的调试器逐行执行代码,观察程序状态。,4、 检查作用域: 确保变量和函数在使用时处于正确的声明作用域内。,5、 查阅文档: 如果错误涉及某个特定的库或框架,查阅官方文档了解用法和限制。,6、 搜索问题: 如果错误信息不够明确,尝试将错误信息复制到搜索引擎中,查看是否有其他开发者遇到过类似问题。,7、 简化问题: 尝试简化代码,移除部分代码,以便更专注于问题本身。,8、 同行评审: 让同事或者社区成员帮忙审查代码,有时候外部的视角更容易发现问题。,9、 构建和测试: 确保你的代码在本地构建和测试过程中不会出现错误。,10、 持续学习: 学习常见的错误类型和它们的解决方法,有助于提高解决问题的效率。,面对错误,保持冷静和耐心是非常重要的,编程是一个不断学习和解决问题的过程,通过解决报错,你可以更深入地理解语言特性和编程模式,当遇到难以解决的问题时,不妨休息一下,换一个思路再继续。, ,var a = 5 function test() { console.log(a) } test() var b = ‘hello,SyntaxError: Invalid or unexpected token,var a = ‘hello’; console.log(a.toFixed(2));,TypeError: a.toFixed is not a function,console.log(b);
在Web开发中,我们经常需要从HTML页面中提取内容,这可能是因为我们需要分析网页结构,或者将网页内容导入到其他应用程序中,有多种方法可以调用HTML页面内容,以下是一些常用的技术:,1、使用Python的requests库和BeautifulSoup库,requests库是一个用于发送HTTP请求的Python库,而BeautifulSoup库是一个用于解析HTML和XML文档的Python库,通过这两个库,我们可以很容易地从HTML页面中提取所需的内容。,确保已经安装了requests和BeautifulSoup库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的Python脚本来调用HTML页面内容:,2、使用JavaScript的Fetch API和DOM操作,Fetch API是一个现代的JavaScript函数,用于发送HTTP请求并获取响应,通过结合DOM操作,我们可以在浏览器端轻松地调用HTML页面内容。,以下是一个使用Fetch API和DOM操作的JavaScript示例:,3、使用Java的Jsoup库,Jsoup是一个用于处理实际世界HTML的Java库,它提供了非常方便的API来提取和操作数据,以及清理用户提交的内容,通过Jsoup,我们可以在Java应用程序中轻松地调用HTML页面内容。,确保已经安装了Jsoup库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的Java程序来调用HTML页面内容:,4、使用PHP的cURL库和DOMDocument类,cURL是一个强大的工具,可以用来获取或发送数据,包括HTTP、HTTPS等协议,通过结合DOMDocument类,我们可以在PHP应用程序中轻松地调用HTML页面内容。,确保已经安装了cURL库,如果没有安装,可以使用以下命令进行安装:,接下来,我们可以编写一个简单的PHP程序来调用HTML页面内容:, ,pip install requests pip install beautifulsoup4,import requests from bs4 import BeautifulSoup 发送HTTP请求并获取HTML内容 url = ‘https://www.example.com’ response = requests.get(url) html_content = response.text 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(html_content, ‘html.parser’) 提取所需内容,例如提取所有的段落标签<p> paragraphs = soup.find_all(‘p’) for p in paragraphs: print(p.text),// 发送HTTP请求并获取HTML内容 fetch(‘https://www.example.com’) .then(response => response.text()) .then(html_content => { // 使用DOM操作提取所需内容,例如提取所有的段落标签<p> const paragraphs = document.querySelectorAll(‘p’); paragraphs.forEach(p => { console.log(p.textContent); }); });,mvn dependency:get DgroupId=org.jsoup DartifactId=jsoup Dversion=1.14.3,import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Main { public static void main(String[] args) { try { // 发送HTTP请求并获取HTML内容 Document doc = Jsoup.connect(“https://www.example.com”).get(); // 提取所需内容,例如提取所有的段落标签<p> Elements paragraphs = doc.select(“p”); for (Element p : paragraphs) { System.out.println(p.text()); } } catch (IOException e) { e.printStackTrace(); } } }