优惠码 第114页

场景介绍 为了给用户展示存储设备信息,开发者可以使用数据存储管理接口获取存储设备视图信息,也可以根据用户提供的文件名获取对应存储设备的视图信息。 开放能力介绍 数据存储管理为开发者提供下面几种功能,具体的API参考。 功能分类 类名 接口名 描述 查询设备视图 ohos.data.usage.DataUsage getVolumes() 获取当前用户可用的设备列表视图。 getVolume(File file) 获取存储该文件的存储设备视图。 getVolume(Context context, Uri uri) 获取该URI对应文件所在的存储设备视图。 getDiskMountedStatus() 获取默认存储设备的挂载状态。 getDiskMountedStatus(File path) 获取存储该文件设备的挂载状态。 isDiskPluggable() 默认存储设备是否为可插拔设备。 isDiskPluggable(File path) 存储该文件的设备是否为可插拔设备。 isDiskEmulated() 默认存储设备是否为虚拟设备。 isDiskEmulated(File path) 存储该文件的设备是否为虚拟设备。 查询设备视图属性 ohos.data.usage.Volume isEmulated() 该设备是否是虚拟存储设备。 isPluggable() 该设备是否支持插拔。 getDescription() 获取设备描述信息。 getState() 获取设备挂载状态。 getVolUuid() 获取设备唯一标识符。 开发步骤 查询设备视图 调用查询设备视图接口。 // 获取默认存储设备挂载状态 MountState status = DataUsage.getDiskMountedStatus(); // 获取存储设备列表 Optional<List<Volume>> list = DataUsage.getVolumes(); // 默认存储设备是否为可插拔设备 boolean pluggable = DataUsage.isDiskPluggable(); 查询设备视图属性 调用查询设备视图接口获取某个设备视图 Volume。 调用 Volume 的接口即可查询视图属性。 // 获取example.txt 文件所在的存储设备的视图属性 Optional<Volume> volume = DataUsage.getVolume(new File("/sdcard/example.txt")); volume.ifPresent(theVolume -> { System.out.println(theVolume.isEmulated()); System.out.println(theVolume.isPluggable()); System.out.println(theVolume.getDescription()); System.out.println(theVolume.getVolUuid()); } );
数据存储管理指导开发者基于 HarmonyOS 进行存储设备(包含本地存储、SD 卡、U 盘等)的数据存储管理能力的开发,包括获取存储设备列表,获取存储设备视图等。 基本概念 数据存储管理 数据存储管理包括了获取存储设备列表,获取存储设备视图,同时也可以按照条件获取对应的存储设备视图信息。 设备存储视图 存储设备的抽象表示,提供了接口访问存储设备的自身信息。 运作机制 用统一的视图结构可以表示各种存储设备,该视图结构的内部属性会因为设备的不同而不同。每个存储设备可以抽象成两部分,一部分是存储设备自身信息区域,一部分是用来真正存放数据的区域。 图1 存储设备视图
场景介绍 索引源应用,一般为有持久化数据的应用,可以通过融合搜索接口为其应用数据建立索引,并配置全局搜索可搜索实体,帮助用户通过全局搜索应用查找本应用内的数据。应用本身也提供搜索框时,也可直接在应用内部通过融合搜索接口实现全文搜索功能。 接口说明 HarmonyOS 中的融合搜索为开发者提供以下几种能力,详见API参考。 类名 接口名 描述 SearchAbility public List<IndexData> insert(String groupId, String bundleName, List<IndexData> indexDataList) 索引插入 public List<IndexData> update(String groupId, String bundleName, List<IndexData> indexDataList) 索引更新 public List<IndexData> delete(String groupId, String bundleName, List<IndexData> indexDataList) 索引删除 SearchSession public int getSearchHitCount(String queryJsonStr) 搜索命中结果数量 public List<IndexData> search(String queryJsonStr, int start, int limit) 分页搜索 public List<Recommendation> groupSearch(String queryJsonStr, int groupLimit) 分组搜索 开发步骤 实例化 SearchAbility,连接融合搜索服务。 SearchAbility searchAbility = new SearchAbility(context); CountDownLatch lock = new CountDownLatch(1); // 连接服务 searchAbility.connect(new ServiceConnectCallback() { @Override public void onConnect() { lock.countDown(); } @Override public void onDisconnect() { } }); // 等待回调,最长等待时间可自定义 lock.await(3000, TimeUnit.MILLISECONDS); // 连接失败可重试 设置索引属性。 // 构造索引属性 List<IndexForm> indexFormList = new ArrayList<>(); IndexForm primaryKey = new IndexForm("id", IndexType.NO_ANALYZED, true, true, false); // 主键,不分词 indexFormList.add(primaryKey); IndexForm title = new IndexForm("title", IndexType.ANALYZED, false, true, true); // 分词 indexFormList.add(title); IndexForm tagType = new IndexForm("tag_type", IndexType.SORTED, false, true, false); // 分词,同时支持排序、分组 indexFormList.add(tagType); IndexForm ocrText = new IndexForm("ocr_text", IndexType.SORTED_NO_ANALYZED, false, true, false); // 支持排序、分组,不分词,所以也支持范围搜索 indexFormList.add(ocrText); IndexForm dateTaken = new...
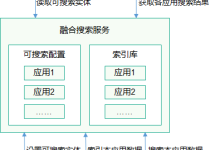
HarmonyOS 融合搜索为开发者提供搜索引擎级的全文搜索能力,可支持应用内搜索和系统全局搜索,为用户提供更加准确、高效的搜索体验。 基本概念 全文索引 记录字或词的位置和次数等属性,建立的倒排索引。 全文搜索 通过全文索引进行匹配查找结果的一种搜索引擎技术。 全局搜索 可以在系统全局统一的入口进行的搜索行为。 全局搜索应用 HarmonyOS 上提供全局搜索入口的应用,一般为桌面下拉框或悬浮搜索框。 索引源应用 通过融合搜索索引接口对其数据建立索引的应用。 可搜索配置 每个索引源应用应该提供一个包括应用包名、是否支持全局搜索等信息的可搜索实体,以便全局搜索应用发起搜索。 群组 经过认证的可信设备圈,可从账号模块获取群组 ID。 索引库 一种搜索引擎的倒排索引库,包含多个索引文件的整个目录构成一个索引库。 索引域 索引数据的字段名,比如一张图片有文件名、存储路径、大小、拍摄时间等,文件名就是其中的一个索引域。 索引属性 描述索引域的信息,包括索引类型、是否为主键、是否存储、是否支持分词等。 运作机制 索引源应用通过融合搜索接口设置可搜索实体,并为其数据内容构建全文索引。全局搜索应用接收用户发起的搜索请求,遍历支持全局搜索的可搜索实体,解析用户输入并构造查询条件,最后通过融合搜索接口获取各应用搜索结果。 图1 融合搜索运作示意图 约束与限制 构建索引或者发起搜索前,索引源应用必须先设置索引属性,并且必须有且仅有一个索引域设置为主键,且主键索引域不能分词,索引和搜索都会使用到索引属性。 索引源应用的数据发生变动时,开发者应同步通过融合搜索索引接口更新索引,以保证索引和应用原始数据的一致性。 批量创建、更新、删除索引时,应控制单次待索引内容大小,建议分批创建索引,防止内存溢出。 分页搜索和分组搜索应控制每页返回结果数量,防止内存溢出。 构建和搜索本机索引时,应该使用提供的 SearchParameter.DEFAULT_GROUP 作为群组 ID,分布式索引使用通过账号模块获取的群组ID。 搜索时需先创建搜索会话,并务必在搜索结束时关闭搜索会话,释放内存资源。 使用融合搜索服务接口需要在“config.json”配置文件中添加“ohos.permission.ACCESS_SEARCH_SERVICE”权限。 搜索时的 SearchParamter.DEVICE_ID_LIST 必须与创建索引时的deviceId一致。
场景介绍 应用可以通过分布式文件服务实现多个设备间的文件共享,设备 1 上的应用A创建了分布式文件 a,设备 2 上的应用A能够通过分布式文件服务读写设备 1 上的文件 a。 接口说明 分布式文件兼容 POSIX 文件操作接口,应用使用 Context.getDistributedDir() 接口获取目录后,可以直接使用 libc 或 JDK 访问分布式文件。 接口名 描述 Context.getDistributedDir() 获取文件的分布式目录 开发步骤 应用可以通过 Context.getDistributedDir() 接口获取属于自己的分布式目录,然后通过 libc 或 JDK 接口,在该目录下创建、删除、读写文件或目录。 设备 1 上的应用 A 创建文件 hello.txt,并写入内容”Hello World”。 Context context; ... // context初始化 File distDir = context.getDistributedDir(); String filePath = distDir + File.separator + "hello.txt"; FileWriter fileWriter = new FileWriter(filePath,true); fileWriter.write("Hello World"); fileWriter.close(); 设备 2 上的应用 A 通过 Context.getDistributedDir() 接口获取分布式目录。 设备 2 上的应用 A 读取文件 hello.txt。 FileReader fileReader = new FileReader(filePath); char[] buffer = new char[1024]; fileReader.read(buffer); fileReader.close(); System.out.println(buffer);
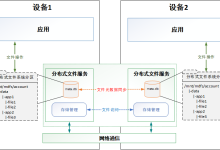
分布式文件服务能够为用户设备中的应用程序提供多设备之间的文件共享能力,支持相同帐号下同一应用文件的跨设备访问,应用程序可以不感知文件所在的存储设备,能够在多个设备之间无缝获取文件。 基本概念 分布式文件 分布式文件是指依赖于分布式文件系统,分散存储在多个用户设备上的文件,应用间的分布式文件目录互相隔离,不同应用的文件不能互相访问。 文件元数据 文件元数据是用于描述文件特征的数据,包含文件名,文件大小,创建、访问、修改时间等信息。 运作机制 分布式文件服务采用无中心节点的设计,每个设备都存储一份全量的文件元数据和本设备上产生的分布式文件,元数据在多台设备间互相同步,当应用需要访问分布式文件时,分布式文件服务首先查询本设备上的文件元数据,获取文件所在的存储设备,然后对存储设备上的分布式文件服务发起文件访问请求,将文件内容读取到本地。 图1 分布式文件服务运作示意图 约束与限制 应用程序如需使用分布式文件服务完整功能,需要申请 ohos.permission.DISTRIBUTED_DATASYNC 权限。 多个设备需要打开蓝牙,连接同一 WLAN 局域网,登录相同华为帐号才能实现文件的分布式共享。 存在多设备并发写的场景下,为了保证文件独享,开发者需要对文件进行加锁保护。 应用访问分布式文件时,如果文件所在设备离线,文件不能访问。 非持锁情况下,并发写冲突时,后一次会覆盖前一次。 网络情况差时,访问存储在远端的分布式文件时,可能会长时间不返回或返回失败,应用需要考虑这种场景的处理。 当两台设备有同名文件时,同步元数据时会产生冲突,分布式文件服务根据时间戳将文件按创建的先后顺序重命名,为避免此场景,建议应用在文件名上做设备区分,例如,deviceID+时间戳。
场景介绍 分布式数据服务主要实现对用户设备中应用程序的数据内容的分布式同步。当设备 1 上的应用 A 在分布式数据库中增、删、改数据后,设备2上的应用 A 也可以获取到该数据库变化。可在分布式图库、信息、通讯录、文件管理器等场景中使用。 接口说明 HarmonyOS 系统中的分布式数据服务模块为开发者提供下面几种功能: 功能分类 接口名称 描述 分布式数据库创建、打开、关闭和删除。 isCreateIfMissing() 数据库不存在时是否创建。 setCreateIfMissing(boolean isCreateIfMissing) 数据库不存在时是否创建。 isEncrypt() 获取数据库是否加密。 setEncrypt(boolean isEncrypt) 设置数据库是否加密。 getStoreType() 获取分布式数据库的类型。 setStoreType(KvStoreType storeType) 设置分布式数据库的类型。 KvStoreType.DEVICE_COLLABORATION 设备协同分布式数据库类型。 KvStoreType.SINGLE_VERSION 单版本分布式数据库类型。 getKvStore(Options options, String storeId) 根据Options配置创建和打开标识符为 storeId 的分布式数据库。 closeKvStore(KvStore kvStore) 关闭分布式数据库。 deleteKvStore(String storeId) 删除分布式数据库。 分布式数据增、删、改、查。 getStoreId() 根据配置构造帐号键值数据库管理类实例。 putBoolean(String key, boolean value)putInt(String key, int value)putFloat(String key, float value)putDouble(String key, double value)putString(String key, String value)putByteArray(String key, byte[] value)putBatch(List<Entry> entries) 插入和更新数据。 delete(String key)deleteBatch(List<String> keys) 删除数据。 getInt(String key)getFloat(String key)getDouble(String key)getString(String key)getByteArray(String key)getEntries(String keyPrefix) 查询数据。 分布式数据谓词查询。 select()reset()equalTo(String field, int value)equalTo(String field, long value)equalTo(String field, double value)equalTo(String field, String value)equalTo(String field, boolean value)notEqualTo(String field, int value)notEqualTog(String field, long value)notEqualTo(String field, boolean value)notEqualTo(String field, String value)notEqualTo(String field, double value)greaterThan(String field, int value)greaterThan(String field, long value)greaterThan(String field, double value)greaterThan(String field, String value)lessThan(String field, int value)lessThan(String field, long value)lessThan(String field, double value)lessThan(String field, String value)greaterThanOrEqualTo(String field, int value)greaterThanOrEqualTo(String field, long value)greaterThanOrEqualTo(String field, double value)greaterThanOrEqualTo(String field, String value)lessThanOrEqualTo(String field, int value)lessThanOrEqualTo(String field, long value)lessThanOrEqualTo(String field, double value)lessThanOrEqualTo(String field, String value)isNull(String field)orderByDesc(String field)orderByAsc(String field)limit(int number, int offset)like(String field, String value)unlike(String field, String value)inInt(String field, List<Integer> valueList)inLong(String field, List<Long> valueList)inDouble(String field, List<Double> valueList)inString(String field, List<String> valueList)notInInt(String field, List<Integer> valueList)notInLong(String field, List<Long> valueList)notInDouble(String field, List<Double> valueList)notInString(String field, List<String> valueList)and()or() 对于Schema数据库谓词查询数据。 订阅分布式数据变化。 subscribe(SubscribeType subscribeType, KvStoreObserver observer) 订阅数据库中数据的变化。 分布式数据同步。 sync(List<String> deviceIdList, SyncMode mode) 在手动模式下,触发数据库同步。 开发步骤 以单版本分布式数据库为例,说明开发步骤。 根据配置构造分布式数据库管理类实例。 根据应用上下文创建 KvManagerConfig 对象。 创建分布式数据库管理器实例。 以下为创建分布式数据库管理器的代码示例: Context context; ... KvManagerConfig config = new KvManagerConfig(context); KvManager kvManager = KvManagerFactory.getInstance().createKvManager(config); 获取/创建单版本分布式数据库。 声明需要创建的单版本分布式数据库 ID 描述。 创建单版本分布式数据库。 以下为创建单版本分布式数据库的代码示例: Options CREATE = new Options(); CREATE.setCreateIfMissing(true).setEncrypt(false).setKvStoreType(KvStoreType.SINGLE_VERSION); String storeID = "testApp"; SingleKvStore singleKvStore = kvManager.getKvStore(CREATE, storeID); 订阅分布式数据变化。 \1. 客户端需要实现KvStoreObserver接口。 \2. 构造并注册KvStoreObserver实例。 以下为订阅单版本分布式数据库所有(本地及远端)数据变化通知的代码示例: class KvStoreObserverClient implements KvStoreObserver() { @Override public void onChange(ChangeNotification notification) { List<Entry> insertEntries = notification.getInsertEntries(); List<Entry> updateEntries =...
分布式数据服务(Distributed Data Service,DDS) 为应用程序提供不同设备间数据库数据分布式的能力。通过调用分布式数据接口,应用程序将数据保存到分布式数据库中。通过结合帐号、应用和数据库三元组,分布式数据服务对属于不同的应用的数据进行隔离,保证不同应用之间的数据不能通过分布式数据服务互相访问。在通过可信认证的设备间,分布式数据服务支持应用数据相互同步,为用户提供在多种终端设备上一致的数据访问体验。 基本概念 KV数据模型 “KV数据模型”是“Key-Value 数据模型”的简称,“Key-Value”即“键-值”。它是一种 NoSQL 类型数据库,其数据以键值对的形式进行组织、索引和存储。 KV 数据模型适合不涉及过多数据关系和业务关系的业务数据存储,比 SQL 数据库存储拥有更好的读写性能,同时因在分布式场景中降低了数据库版本兼容和数据同步过程中冲突解决的复杂度而被广泛使用。分布式数据库也是基于 KV 数据模型,对外提供 KV 类型的访问接口。 分布式数据库事务性 分布式数据库事务支持本地事务(和传统数据库的事务概念一致)和同步事务,同步事务是指在设备之间同步数据时,是以本地事务为单位进行同步,一次本地事务的修改要么都同步成功,要么都同步失败。 分布式数据库一致性 在分布式场景中一般会涉及多个设备,组网内设备之间看到的数据是否一致称为分布式数据库的一致性。分布式数据库一致性可以分为强一致性、弱一致性和最终一致性。 强一致性:是指某一设备成功增、删、改数据后,组网内设备对该数据的读取操作都将得到更新后的值。 弱一致性:是指某一设备成功增、删、改数据后,组网内设备可能能读取到本次更新数据,也可能读取不到,不能保证在多长时间后每个设备的数据一定是一致的。 最终一致性:是指某一设备成功增、删、改数据后,组网内设备可能读取不到本次更新数据,但在某个时间窗口之后组网内设备的数据能够达到一致状态。 强一致性对分布式数据的管理要求非常高,在服务器的分布式场景可能会遇到。因为移动终端设备的不常在线、以及无中心的特性,分布式数据服务不支持强一致,只支持最终一致性。 分布式数据库同步 底层通信组件完成设备发现和认证,会通知上层应用程序(包括分布式数据服务)设备上线。收到设备上线的消息后分布式数据服务可以在两个设备之间建立加密的数据传输通道,利用该通道在两个设备之间进行数据同步。 分布式数据服务提供了两种同步模式:手动**同步和自动同步模式。手动同步**模式完全由应用程序调用接口来触发,并且支持指定同步的设备列表和同步模式(PULL、PUSH和PULL_PUSH三种同步模式)。自动同步模式由分布式数据库来完成数据同步(同步时机包括设备上线、应用程序修改数据等),业务不感知同步操作。 单版本分布式数据库 单版本是指数据在本地保存是以单个KV条目为单位的方式保存,对每个Key最多只保存一个条目项,当数据在本地被用户修改时,不管它是否已经被同步出去,均直接在这个条目上进行修改。同步也以此为基础,按照它在本地被写入或更改的顺序将当前最新一次修改逐条同步至远端设备。 设备协同分布式数据库 设备协同分布式数据库建立在单版本分布式数据库之上,对应用程序存入的 KV 数据中的 Key 前面拼接了本设备的 DeviceID 标识符,这样能保证每个设备产生的数据严格隔离,底层按照设备的维度管理这些数据,设备协同分布式数据库支持以设备的维度查询分布式数据,但是不支持修改远端设备同步过来的数据。 分布式数据库冲突解决策略 分布式数据库多设备提交冲突场景,在给提交冲突做合并的过程中,如果多个设备同时修改了同一数据,则称这种场景为数据冲突。数据冲突采用默认冲突解决策略,基于提交时间戳,取时间戳较大的提交数据,当前不支持定制冲突解决策略。 数据库Schema化管理与谓词查询 单版本数据库支持在创建和打开数据库时指定 Schema,数据库根据 Schema 定义感知 KV 记录的 Value 格式,以实现对 Value 值结构的检查,并基于 Value 中的字段实现索引建立和支持谓词查询。 分布式数据库备份能力 提供分布式数据库备份能力,业务通过设置 backup 属性为 true,可以触发分布式数据服务每日备份。当分布式数据库发生损坏,分布式数据服务会删除损坏数据库,并且从备份数据库中恢复上次备份的数据。如果不存在备份数据库,则创建一个新的数据库。同时支持加密数据库的备份能力。 运作机制 分布式数据服务支撑 HarmonyOS 系统上应用程序数据库数据分布式管理,支持数据在相同帐号的多端设备之间相互同步,为用户在多端设备上提供一致的用户体验,分布式数据服务包含五部分: 服务接口 分布式数据服务提供专门的数据库创建、数据访问、数据订阅等接口给应用程序调用,接口支持 KV 数据模型,支持常用的数据类型,同时确保接口的兼容性、易用性和可发布性。 服务组件 服务组件负责服务内元数据管理、权限管理、加密管理、备份和恢复管理以及多用户管理等、同时负责初始化底层分布式 DB 的存储组件、同步组件和通信适配层。 存储组件 存储组件负责数据的访问、数据的缩减、事务、快照、数据库加密,以及数据合并和冲突解决等特性。 同步组件 同步组件连结了存储组件与通信组件,其目标是保持在线设备间的数据库数据一致性,包括将本地产生的未同步数据同步给其他设备,接收来自其他设备发送过来的数据,并合并到本地设备中。 通信适配层 通信适配层负责调用底层公共通信层的接口完成通信管道的创建、连接,接收设备上下线消息,维护已连接和断开设备列表的元数据,同时将设备上下线信息发送给上层同步组件,同步组件维护连接的设备列表,同步数据时根据该列表,调用通信适配层的接口将数据封装并发送给连接的设备。 应用程序通过调用分布式数据服务接口实现分布式数据库创建、访问、订阅功能,服务接口通过操作服务组件提供的能力,将数据存储至存储组件,存储组件调用同步组件实现将数据同步,同步组件使用通信适配层将数据同步至远端设备,远端设备通过同步组件接收数据,并更新至本端存储组件,通过服务接口提供给应用程序使用。 图1 数据分布式运作示意图 约束与限制 应用程序如需使用分布式数据服务完整功能,需要申请 ohos.permission.DISTRIBUTED_DATASYNC 权限。 分布式数据服务的数据模型仅支持 KV 数据模型,不支持外键、触发器等关系型数据库中的技术点。 分布式数据服务支持的 KV 数据模型规格: 设备协同数据库,Key 最大支持 896Byte,Value 最大支持 4MB – 1Byte。 单版本数据库,Key 最大支持 1KB,Value 最大支持 4MB – 1Byte。 每个应用程序最多支持同时打开 16 个 KvStore。 由于支持的存储类型不完全相同等原因,分布式数据服务无法完全代替业务沙箱内数据库数据的 存储功能,开发人员需要确定要做分布式同步的数据,把这些数据保存到分布式数据服务中。 分布式数据服务当前不支持应用程序自定义冲突解决策略。
场景介绍 轻量级偏好数据库是轻量级存储,主要用于保存应用的一些常用配置,并不适合存储大量数据和频繁改变数据的场景。用户的数据保存在文件中,可以持久化的存储在设备上。需要注意的是用户访问的实例包含文件所有数据,并一直加载在设备的内存中,并通过轻量级偏好数据库的 API 完成数据操作。 接口说明 轻量级偏好数据库向本地应用提供了操作偏好型数据库的 API,支持本地应用读写少量数据及观察数据变化。数据存储形式为键值对,键的类型为字符串型,值的存储数据类型包括整型、字符串型、布尔型、浮点型、长整型、字符串型 Set 集合。 创建数据库 通过数据库操作的辅助类可以获取到要操作的 Preferences 实例,用于进行数据库的操作。 类名 接口名 描述 DatabaseHelper Preferences getPreferences(String name) 获取文件对应的 Preferences 单实例,用于数据操作。 查询数据 通过调用 Get 系列的方法,可以查询不同类型的数据。 类名 接口名 描述 Preferences int getInt(String key, int defValue) 获取键对应的 int 类型的值。 Preferences float getFloat(String key, float defValue) 获取键对应的 float 类型的值。 插入数据 通过 Put 系列的方法可以修改 Preferences 实例中的数据,通过 flush 或者 flushSyn c将 Preferences 实例持久化。 类名 接口名 描述 Preferences Preferences putInt(String key, int value) 设置 Preferences 实例中键对应的 int 类型的值。 Preferences Preferences putString(String key, String value) 设置 Preferences 实例中键对应的 String 类型的值。 Preferences void flush() 将 Preferences 实例异步写入文件。 Preferences boolean flushSync() 将 Preferences 实例同步写入文件。 观察数据变化 轻量级偏好数据库还提供了一系列的接口变化回调,用于观察数据的变化。开发者可以通过重写 onChange 方法来定义观察者的行为。 类名 接口名 描述 Preferences void registerObserver(PreferencesObserver preferencesObserver) 注册观察者,用于观察数据变化。 Preferences void unRegisterObserver(PreferencesObserver preferencesObserver) 注销观察者。 Preferences.PreferencesObserver void onChange(Preferences preferences, String key) 观察者的回调方法,任意数据变化都会回调该方法。 删除数据文件 通过调用以下两种接口,可以删除数据文件。 类名 接口名 描述 DatabaseHelper boolean deletePreferences(String name) 删除文件和文件对应的Preferences单实例。 DatabaseHelper void removePreferencesFromCache(String name) 删除文件对应的Preferences单实例。 移动数据库文件 类名 接口名 描述 DatabaseHelper boolean movePreferences(Context sourceContext, String sourceName, String targetName) 移动数据库文件。 开发步骤 准备工作,导入对轻量级偏好数据库 SDK 到开发环境。 获取 Preferences 实例。 读取指定文件,将数据加载到 Preferences 实例,用于数据操作。 DatabaseHelper databaseHelper = new DatabaseHelper(context);// context入参类型为ohos.app.Context String fileName = "name"; Preferences preferences = databaseHelper.getPreferences(fileName); 从指定文件读取数据。 首先获取指定文件对应的 Preferences...
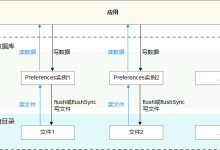
轻量级偏好数据库主要提供轻量级 Key-Value 操作,支持本地应用存储少量数据,数据存储在本地文件中,同时也加载在内存中的,所以访问速度更快,效率更高。轻量级偏好数据库属于非关系型数据库,不宜存储大量数据,经常用于操作键值对形式数据的场景。 基本概念 Key-Value 数据库 一种以键值对存储数据的一种数据库,类似 Java 中的 map。Key 是关键字,Value 是值。 非关系型数据库 区别于关系数据库,不保证遵循 ACID(Atomic、Consistency、Isolation及Durability)特性,不采用关系模型来组织数据,数据之间无关系,扩展性好。 偏好 数据 用户经常访问和使用的数据。 运作机制 本模块提供偏好型数据库的操作类,应用通过这些操作类完成数据库操作。 借助 DatabaseHelper API,应用可以将指定文件的内容加载到 Preferences 实例,每个文件最多有一个 Preferences 实例,系统会通过静态容器将该实例存储在内存中,直到应用主动从内存中移除该实例或者删除该文件。 获取到文件对应的 Preferences 实例后,应用可以借助 Preferences API,从 Preferences 实例中读取数据或者将数据写入 Preferences 实例,通过 flush 或者 flushSync 将 Preferences 实例持久化。 图1 轻量级偏好数据库运作机制 约束与限制 Key 键为 String 类型,要求非空且大小不超过 80 个字符。 如果 Value 值为 String 类型,可以为空但是长度不超过 8192 个字符。 存储的数据量应该是轻量级的,建议存储的数据不超过一万条,否则会在内存方面产生较大的开销。