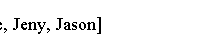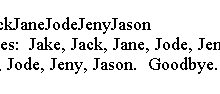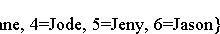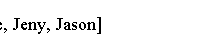Java教程 第46页

Java流 – Java流查找 Streams API支持对流元素的不同类型的查找操作。 Stream接口中的以下方法用于执行查找操作: Optional<T> findAny() Optional<T> findFirst() 诸如IntStream,LongStream和DoubleStream的原始类型流也包含与谓词一起使用的相同方法和用于原语类型的可选方法。 所有查找操作都是终端操作。它们也是短路操作。短路操作可以不必处理整个流以返回结果。 以下代码显示如何对流执行查找操作。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; import java.util.Optional; public class Main { public static void main(String[] args) { List<Employee> persons = Employee.persons(); // Find any male Optional<Employee> anyMale = persons.stream().filter(Employee::isMale).findAny(); if (anyMale.isPresent()) { System.out.println("Any male: " + anyMale.get()); } else { System.out.println("No male found."); } // Find the first male Optional<Employee> firstMale = persons.stream().filter(Employee::isMale).findFirst(); if (firstMale.isPresent()) { System.out.println("First male: " + anyMale.get()); } else { System.out.println("No male found."); } } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate...
Java流转换收集器结果 我们可以将收集器的结果转换为不同的类型。 Collectors类的collectingAndThen()方法定义如下。 collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher) 第一个参数是收集数据的收集器。 第二个参数是转换结果的转换器。 例子 以下代码返回收集数据的不可更改视图。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.Collections; import java.util.List; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { List<String> names = Employee.persons() .stream() .map(Employee::getName) .collect(Collectors.collectingAndThen(Collectors.toList(), result -> Collections.unmodifiableList(result))); System.out.println(names); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name = name; this.gender = gender; this.dob = dob; this.income = income; } public String getName() { return name; } public static List<Employee> persons() { Employee p1 = new Employee(1, "Jake", Gender.MALE, LocalDate.of(1971,...
Java流 – Java流分区 分区是分组的一种特殊情况。 分组数据基于从函数返回的键。可能有很多组。 分区仅处理基于谓词的两个组。评估为true的值为一个组,false为另一个组。 partitioningBy()方法,它收集映射中的数据,其键的总是布尔类型,在两个版本中重载。 partitioningBy(Predicate<? super T> predicate) partitioningBy(Predicate<? super T> predicate, Collector<? super T,A,D> downstream) 例子 第一个版本的partitioningBy()方法返回基于谓词执行分区的收集器。 以下代码显示如何根据性别对employee进行分区。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { Map<Boolean, List<Employee>> partionedByMaleGender = Employee.persons() .stream() .collect(Collectors.partitioningBy(Employee::isMale)); System.out.println(partionedByMaleGender); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name = name; this.gender = gender; this.dob = dob; this.income = income; } public boolean isMale() { return this.gender == Gender.MALE; } public static List<Employee>...
Java流分组 Collectors类中的groupingBy()方法返回一个收集器,用于在将数据收集到Map之前对数据进行分组。 它类似于SQL中的“group by”子句。 groupingBy()方法是重载的,它有三个版本: groupingBy(Function<? super T,? extends K> classifier) groupingBy(Function<? super T,? extends K> classifier, Collector<? super T,A,D> downstream) groupingBy(Function<? super T,? extends K> classifier, Supplier<M> mapFactory, Collector<? super T,A,D> downstream) 在前两个版本中,收集器负责为您创建Map对象。第三个版本允许我们指定一个用作工厂的Supplier来获取Map对象。 classifier 函数生成地图中的键。 collector 对与每个键相关联的值执行简化操作。 以下代码显示了如何按性别和计算每个组中的人数。 Collectors类的counting()方法返回要计数的Collector流中的元素数。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { Map<Employee.Gender, Long> countByGender = Employee.persons() .stream() .collect(Collectors.groupingBy(Employee::getGender, Collectors.counting())); System.out.println(countByGender); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name = name; this.gender = gender;...
Java流连接 Collectors类的joining()方法返回一个收集器,它连接CharSequence流,并将结果作为String返回。 joining()方法是重载的,它有三个版本: joining() 连接所有元素 joining(CharSequence delimiter)使用在两个元素之间使用的分隔符。 joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix)使用分隔符,前缀和后缀。 前缀将添加到开头,后缀将添加到结尾。 以下代码显示如何使用joining()方法。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { List<Employee> persons = Employee.persons(); String names = persons.stream() .map(Employee::getName) .collect(Collectors.joining()); String delimitedNames = persons.stream() .map(Employee::getName) .collect(Collectors.joining(", ")); String prefixedNames = persons.stream() .map(Employee::getName) .collect(Collectors.joining(", ", "Hello ", ". Goodbye.")); System.out.println("Joined names: " + names); System.out.println("Joined, delimited names: " + delimitedNames); System.out.println(prefixedNames); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name =...
Java流 – Java流收集映射 我们可以从流中收集数据到映射。 在三个版本中重载的toMap()方法Collectors类返回一个收集器以在Map中收集数据。 toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper) toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper, BinaryOperator<U> mergeFunction) toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper, BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier) toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper) 第一个版本有两个参数。这两个参数都是一个函数。 第一个参数将流元素映射到映射中的键。 第二个参数将流元素映射到映射中的值。 如果重复键,则抛出IllegalStateException。 以下代码在Map<long,String>中收集员工的数据,其中的关键字是员工的ID,值是员工的姓名。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { Map<Long,String> idToNameMap = Employee.persons() .stream() .collect(Collectors.toMap(Employee::getId, Employee::getName)); System.out.println(idToNameMap); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private...
Java流 – Java流收集器 要在Stream中对数据进行分组,我们可以使用 collect()方法的Stream<T>接口。 collect()方法重载了两个版本: <R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner) <R,A> R collect(Collector<? super T,A,R> collector) collect()方法的第一个版本有三个参数: 供应商提供一个可变容器来存储结果。 累加器,将结果累积到可变容器中。 组合器,当并行使用时组合部分结果。 我们使用以下步骤在ArrayList <String>中收集员工姓名。 首先,创建一个供应商,它使用以下语句之一返回一个 ArrayList< String> 以创建供应商: Supplier<ArrayList<String>> supplier = () -> new ArrayList<>(); 要么 Supplier<ArrayList<String>> supplier = ArrayList::new; 第二,创建一个累加器,它接收两个参数,它们是从供应商返回的容器(在这种情况下为ArrayList <String>)。 和流的元素。 累加器将名称添加到列表中。 BiConsumer<ArrayList<String>, String> accumulator = (list, name) -> list.add(name); BiConsumer<ArrayList<String>, String> accumulator = ArrayList::add; 最后,组合器将结果组合成一个 ArrayList<String> 。 组合器仅用于并行流。 以下代码显示如何使用collect()方法来收集列表中所有员工的姓名。 import java.time.LocalDate; import java.time.Month; import java.util.ArrayList; import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) { List<String> names = Employee.persons() .stream() .map(Employee::getName) .collect(ArrayList::new, ArrayList::add, ArrayList::addAll); System.out.println(names); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate...
Java流计数 Streams通过count()方法支持计数操作,该方法将流中的元素数返回为long。 以下代码显示employee流中的元素数量。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) { long personCount = Employee.persons().stream().count(); System.out.println("Person count: " + personCount); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name = name; this.gender = gender; this.dob = dob; this.income = income; } public static List<Employee> persons() { Employee p1 = new Employee(1, "Jake", Gender.MALE, LocalDate.of(1971, Month.JANUARY, 1), 2343.0); Employee p2 = new Employee(2, "Jack", Gender.MALE, LocalDate.of(1972, Month.JULY, 21), 7100.0); Employee p3 = new Employee(3, "Jane", Gender.FEMALE,...
Java流 – Java流聚合 要计算数字流上的和,max,min,average等,我们可以将非数字流映射到数值流类型(IntStream,LongStream或DoubleStream),然后使用专门的方法。 以下代码计算收入的总和。 mapToDouble()方法将 Stream<Employee> 转换为 DoubleStream 。对DoubleStream调用sum()方法。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) { double totalIncome = Employee.persons() .stream() .mapToDouble(Employee::getIncome) .sum(); System.out.println("Total Income: " + totalIncome); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob; private double income; public Employee(long id, String name, Gender gender, LocalDate dob, double income) { this.id = id; this.name = name; this.gender = gender; this.dob = dob; this.income = income; } public double getIncome() { return income; } public static List<Employee> persons() { Employee p1 = new Employee(1, "Jake", Gender.MALE, LocalDate.of(1971, Month.JANUARY, 1), 2343.0); Employee...
Java流 – Java流映射 映射操作对每个元素应用函数以产生另一流。 输入和输出流中的元素数量是相同的。 该操作不修改输入流的元素。 您可以使用Stream <T>接口的以下方法之一对流应用地图操作: <R> Stream<R> map(Function<? super T,? extends R> mapper) DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper) IntStream mapToInt(ToIntFunction<? super T> mapper) LongStream mapToLong(ToLongFunction<? super T> mapper) IntStream,LongStream和DoubleStream也定义了映射函数。支持对IntStream进行映射操作的方法如下: IntStream map(IntUnaryOperator mapper) DoubleStream mapToDouble(IntToDoubleFunction mapper) LongStream mapToLong(IntToLongFunction mapper) <U> Stream<U> mapToObj(IntFunction<? extends U> mapper) 以下代码显示如何使用map()将IntStream中的元素映射到其正方形,并在标准输出上打印映射流。 import java.util.stream.IntStream; public class Main { public static void main(String[] args) { IntStream.rangeClosed(1, 5) .map(n -> n * n) .forEach(System.out::println); } } 上面的代码生成以下结果。 例2 以下代码将员工流映射到其名称,并打印映射流。 import java.time.LocalDate; import java.time.Month; import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) { Employee.persons() .stream() .map(Employee::getName) .forEach(System.out::println); } } class Employee { public static enum Gender { MALE, FEMALE } private long id; private String name; private Gender gender; private LocalDate dob;...