Python3 教程 第2页 本章节主要说明 Python 的运算符。举个简单的例子 4 + 5 = 9 。例子中,4 和 5 被称为操作数,”+” 称为运算符。 Python 语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 接下来让我们一个个来学习 Python 的运算符。 Python 算术运算符 以下假设变量 a 为 21,变量 b 为 10: 运算符 描述 实例 + 加 – 两个对象相加 a + b 输出结果 31 – 减 – 得到负数或是一个数减去另一个数 a – b 输出结果 11 * 乘 – 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 210 / 除 – x 除以 y a / b 输出结果 2.1 % 取模 – 返回除法的余数 a % b 输出结果 1 ** 幂 – 返回 x 的 y 次幂 a ** b 为 21 的 10 次方 // 取整除 – 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 以下实例演示了 Python 所有算术运算符的操作: #!/usr/bin/python3 #coding=utf-8 a = 21...
2024-04-01
Python 数字类型用于数值的储存。数值类型是不允许改变的,如果改变数字数据类型的值,将重新分配内存空间。 以下实例在变量赋值时 Number 对象将被创建: var1 = 1 var2 = 10 您也可以使用del语句删除一些数字对象的引用。 del语句的语法是: del var1[,var2[,var3[....,varN]]] 您可以通过使用del语句删除单个或多个对象的引用,例如: del var del var_a, var_b Python 支持三种不同的数值类型: 整型(Int) – 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。 浮点型(float) – 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250) 复数( (complex)) – 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。 我们可以使用十六进制和八进制来代表整数: >>> number = 0xA0F # 十六进制 >>> number 2575 >>> number=0o37 # 八进制 >>> number 31 int float complex 10 0.0 3.14j 100 15.20 45.j -786 -21.9 9.322e-36j 080 32.3e+18 .876j -0490 -90. -.6545+0J -0x260 -32.54e100 3e+26J 0x69 70.2E-12 4.53e-7j Python支持复数,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。 Python 数字类型转换 有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。 int(x) 将x转换为一个整数。 float(x) 将x转换到一个浮点数。 complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。 complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。 以下实例将浮点数变量...
2024-04-01
在编程语言中,将以某种方式(比如通过编号)组合起来的数据元素(如数字,字符串乃至其他数据结构)集合称为数据结构。在python中,最基本的数据结构为序列(sequence,简写为seq)。 所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。 为了更形象的认识序列,可以将它看做是一家旅店,那么店中的每个房间就如同序列存储数据的一个个内存空间,每个房间所特有的房间号就相当于索引值。也就是说,通过房间号(索引)我们可以找到这家旅店(序列)中的每个房间(内存空间)。 在 Python 中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持以下几种通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。 字符串也是一种常见的序列(所以以下的例子以字符串作为),它也可以直接通过索引访问字符串内的字符。 序列索引 序列中,每个元素都有属于自己的编号(索引)。从起始元素开始,索引值从 0 开始递增,如图 1 所示。 序列索引值示意图 除此之外,Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图 2 所示。 负值索引示意图 注意,在使用负值作为列序中各元素的索引值时,是从 -1 开始,而不是从 0 开始。 另一种理解方式是:将序列想象成如下方的一个环: 红色值为元素,绿色值为正索引,蓝色值为负索引 可以发现序列的最后一个元素和第一个元素刚好相邻,方向与正索引的方向刚好相反,所以其负索引值是-1,。该序列有8个元素,所以最后一个负索引(也就是第一个元素)是-8,刚好等于该序列的长度的负值。 无论是采用正索引值,还是负索引值,都可以访问序列中的任何元素。以字符串为例,访问“W3Cschool”的首元素和尾元素,可以使用如下的代码: str="W3Cschool" print(str[0],"==",str[-9]) print(str[8],"==",str[-1]) 输出结果为: W == W l == l 序列切片 切片操作是访问序列中元素的另一种方法,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。 序列实现切片操作的语法格式如下: sname[start : end : step] 其中,各个参数的含义分别是: sname:表示序列的名称; start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,会默认为 0,也就是从序列的开头进行切片; end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度; step:表示在切片过程中,隔几个存储位置(包含当前位置)取一次元素,也就是说,如果 step 的值大于 1,则在进行切片去序列元素时,会“跳跃式”的取元素。如果省略设置 step 的值,则最后一个冒号就可以省略。 例如,对字符串“W3Cschool”进行切片: str="W3Cschool" #取索引区间为[0,2]之间(不包括索引2处的字符)的字符串 print(str[:2]) #隔 1 个字符取一个字符,区间是整个字符串 print(str[::2]) #取整个字符串,此时 [] 中只需一个冒号即可 print(str[:]) 尝试一下 运行结果为: W3 WCcol W3Cschool 序列相加 Python 中,支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。 这里所说的“类型相同”,指的是“+”运算符的两侧序列要么都是列表类型,要么都是元组类型,要么都是字符串。 例如,前面章节中我们已经实现用“+”运算符连接 2 个(甚至多个)字符串,如下所示: protocol = "https://" url = "www.w3cschool.cn" print(protocol+url) 尝试一下 输出结果为: https://www.w3cschool.cn 序列相乘 Python 中,使用数字 n 乘以一个序列会生成新的序列,其内容为原来序列被重复 n 次的结果。例如: str="W3Cschool" print(str*3) 输出结果为: W3CschoolW3CschoolW3Cschool 比较特殊的是,列表类型在进行乘法运算时,还可以实现初始化指定长度列表的功能。例如如下的代码,将创建一个长度为 5 的列表,列表中的每个元素都是 None,表示什么都没有。 #列表的创建用 [],可以指定长度 list = [None]*5 print(list) 尝试一下 输出结果为: [None, None, None, None, None] 检查元素是否包含在序列中...
2024-04-01
字符串(string,简写为str)是 Python 中最常用的数据类型之一。我们可以使用引号( ‘ 或 ” )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 = 'Hello World!' var2 = "W3Cschool" Python 访问字符串中的值 Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。 Python 访问子字符串,可以使用方括号 []来截取字符串(这种方式也被称为切片),字符串的截取的语法格式如下: 变量[头下标:尾下标] python截取的特点是取头下标的值到尾下标的值(尾下标的值不取) 索引值以 0 为开始值,-1 为从末尾的开始位置。 从后面索引 -9 -8 -7 -6 -5 -4 -3 -2 -1 从前面索引 0 1 2 3 4 5 6 7 8 W 3 C s c h o o l 从前面截取 : 1 2 3 4 5 6 7 8 : 从后面截取 : -8 -7 -6 -5 -4 -3 -2 -1 : 以下代码都是取字符C: str="W3cschool" print(str[2:3]) #使用截取方式,用正序进行截取 print(str[2:-6])#使用截取方式,正序和倒序混合使用 print(str[-7:-6])#使用截取方式,使用倒序进行截取 print(str[-7])#使用负索引获取单个字符C print(str[2])#使用正索引获取单个字符C 切片的更多案例: str="W3cschool" #取W3C print(str[:3]) print(str[:-6]) #取sch print(str[3:6]) print(str[-6:-3]) #只有头下标/尾下标的情况 print(str[:3]) #只有尾下标的情况,默认头下标为0(正序的0,也就是字符串开始的地方) #也就是从字符串开头截取到3的位置(也就是W3C) print(str[3:]) #只有头下标的情况,默认尾下标为0(逆序的0,也就是字符串结束的地方) #也就是从3的位置截取到字符串结尾(也就是school) #更多应用 str2 ="https://www.w3cschool.cn/" #截取协议名称 print(str2[:5]) #也就是截取前五位 #截取域名 print(str2[8:-1]) #也就是截取第八位到倒数第一位 尝试一下 Python转义字符 有一些字符因为在python中已经被定义为一些操作(比如单引号和双引号被用来引用字符串),而这些符号我们可能在字符串中需要使用到。为了能够使用这些特殊字符,可以用反斜杠 \ 转义字符(同样地,反斜杠也可以用来转义反斜杠)。如下表: 转义字符 描述...
2024-04-01
列表(list)也是最常用的 Python 数据类型之一,它以一个方括号内包含多个其他数据项(字符串,数字等甚至是另一个列表),数据项间以逗号作为分隔的数据类型。 列表的数据项不需要具有相同的类型。(这点是与其他语言的数组的一个区别) 创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示: list1 = ['Google', 'W3Cschool', 1997, 2000] list2 = [1, 2, 3, 4, 5, 6, 7 ] print ("list1: ", list1) print ("list2: ", list2) 尝试一下 运行结果: list1: ['Google', 'W3Cschool', 1997, 2000] list2: [1, 2, 3, 4, 5, 6, 7] 访问列表中的值 与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。 通过索引列表可以进行截取、组合等操作。 该部分内容和字符串索引和切片内容具有很高的相似性(因为这些都是序列的基本操作),本章不做过多介绍,有需求的同学可以前往字符串章节进行回顾。 索引 0 1 2 3 负索引 -4 -3 -2 -1 值 ‘Google’ ‘W3Cschool’ 1997 2000 以下是列表索引的操作: list1 = ['Google', 'W3Cschool', 1997, 2000] print ("list1的第一项: ", list1[0]) print ("list1的最后一项: ", list1[-1]) 尝试一下 运行结果: list1的第一项: Google list1的最后一项: 2000 以下是列表切片的操作: list1 = ['Google', 'W3Cschool', 1997, 2000] print ("list1的前3项: ", list1[0:3]) print ("list1的2、3项: ", list1[1:3]) 尝试一下 运行结果: list1的前3项: ['Google', 'W3Cschool', 1997] list1的2、3项: ['W3Cschool', 1997] 更新列表 你可以对列表的数据项进行修改或更新,你也可以使用 append() 方法来添加列表项,如下所示: list1 = ['Google', 'W3Cschool', 1997, 2000] print ("list1的第三个元素为:...
2024-04-01
Python 的元组(tuple,简写为tup)与列表类似,不同之处在于元组的元素不能修改。 元组使用小括号(),列表使用方括号[]。 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。 如下实例: tup1 = ('Google', 'W3CSchool', 1997, 2020) tup2 = (1, 2, 3, 4, 5 ) tup3 = "a", "b", "c", "d" # 不需括号也可以 print(type(tup3)) 运行结果: <class 'tuple'> 创建空元组 tup1 = () 元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当做运算符使用。 tup1 = (50,) 元组与字符串类似,下标索引从 0 开始,可以进行截取,组合等。 正索引 0 1 2 3 值 Google W3Cschool 1997 2020 负索引 -4 -3 -2 -1 访问元组 元组可以使用下标索引来访问元组中的值,如下实例: #!/usr/bin/python3 tup1 = ('Google', 'W3CSchool', 1997, 2020) tup2 = (1, 2, 3, 4, 5, 6, 7 ) print ("tup1[0]: ", tup1[0]) print ("tup2[1:5]: ", tup2[1:5]) 尝试一下 以上实例输出结果: tup1[0]: Google tup2[1:5]: (2, 3, 4, 5) 修改元组 元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例: #!/usr/bin/python3 tup1 = (12, 34.56); tup2 = ('abc', 'xyz') # 以下修改元组元素操作是非法的。 # tup1[0] = 100 # 创建一个新的元组 tup3 = tup1 + tup2; print (tup3) 尝试一下...
2024-04-01
在Python3中字典(dictionary ,简写为dict)是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值 (key=>value) 对用冒号 (:) 分割,每个对之间用逗号 (,) 分割,整个字典包括在花括号 ({}) 中 ,格式如下所示: dict = {key1 : value1, key2 : value2 } key(键) value(值) ‘Alice’ ‘2341’ ‘Beth’ ‘9102’ ‘Cecil’ ‘3258’ ‘Danna’ ‘2341’ ‘Steven’ ‘5643’ 键必须是唯一的,但值则不必(上表中Danna和Alice的键是不同的,值却是相同的)。 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。 一个简单的字典实例: dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'} 也可如此创建字典: dict1 = { 'abc': 456 } dict2 = { 'abc': 123, 98.6: 37 } 访问字典里的值 与列表取值类似,但列表取值时使用索引,字典取值时使用key,如下实例: #!/usr/bin/python3 dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'} print ("dict['Name']: ", dict['Name']) print ("dict['Age']: ", dict['Age']) 尝试一下 以上实例输出结果: dict['Name']: W3CSchool dict['Age']: 7 如果用字典里没有的键访问数据,会输出错误如下: #!/usr/bin/python3 dict = {'Name': 'W3CSchool', 'Age': 7, 'Class': 'First'} print ("dict['Alice']: ", dict['Alice']) 尝试一下 以上实例输出结果: Traceback (most recent call last): File "test.py", line 5, in <module> print ("dict['Alice']: ", dict['Alice']) KeyError: 'Alice' 修改字典 向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例: #!/usr/bin/python3 dict...
2024-04-01
集合(set)是一个无序的不重复元素序列。因此在每次运行的时候集合的运行结果的内容都是相同的,但元素的排列顺序却不是固定的,所以本章中部分案例的运行结果会出现与给出结果不同的情况(运行结果不唯一)。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。 创建格式: parame = {value01,value02,...} 或者 set(value) 集合实例: basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} print(basket) # 这里演示的是去重功能 print('orange' in basket) # 快速判断元素是否在集合内 print('crabgrass' in basket) 尝试一下 运行结果: {'pear', 'banana', 'orange', 'apple'} True False 集合的运算: a = set('abracadabra') b = set('alacazam') print(a) print(b) print(a-b) print(a|b) print(a&b) print(a^b) 尝试一下 运行结果: {'b', 'd', 'a', 'c', 'r'} {'l', 'z', 'm', 'a', 'c'} {'r', 'd', 'b'} {'l', 'z', 'b', 'm', 'd', 'a', 'c', 'r'} {'c', 'a'} {'l', 'z', 'b', 'm', 'r', 'd'} a-b(a集合中b没有的元素) b d r 集合a b d r a c a|b(并集) b d r a c l z m 集合b a c l z m a&b(交集) a c ...
2024-04-01
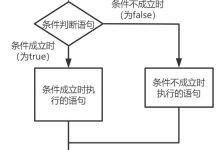
if语句 Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。 Python 中 if 语句的一般形式如下所示: if condition_1: statement_block_1 流程图如下所示: 这种if语句只有在符合条件的时候才会执行代码块内的代码,是一种比较常见的用法。 另一种常见的用法是: if condition_1: statement_block_1 else: statement_block_2 流程图如下所示: 这种语句是一种常用的if-else语句,通常用于二分支结构的条件语句代码。 在一些时候,我们可能需要多分支的条件语句代码,可以在if-else语句中混合elif语句进行使用: Python 中用 elif 代替了else if,所以if语句的关键字为:if – elif – else。 if condition_1: statement_block_1 elif condition_2: statement_block_2 else: statement_block_3 流程图如下所示: 如果 “condition_1” 为 True 将执行 “statement_block_1” 块语句,如果 “condition_1” 为 False,将判断 “condition_2″,如果”condition_2” 为 True 将执行 “statement_block_2” 块语句,如果 “condition_2” 为 False,将执行”statement_block_3″块语句。 使用第一种常用的if语句搭配合适的条件可以实现第二种和第三种语句的全部效果,但在执行效率和代码可读性上会变得比较糟糕。 注意: 1、每个条件后面要使用冒号(:),表示接下来是满足条件后要执行的语句块。 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。 3、在 Python 中没有 switch – case 语句,但在python3.10中添加了用法类似的match-case语句。 match-case语句(python3.10新特性) 在其他语言(比如说经典的C语言)中有一种多分支条件判断语句,可以进行模式匹配(通俗的讲,就是将传入的内容跟多个已存在的样例进行比较,找到相同的案例并按照该案例的代码进行处理,如果没有相同案例就按默认案例进行处理,可以查看其他编程语言的条件语句的Switch相关部分内容进行比较参考)。在python3.10中也引入了这样的新特性。 match-case语句的结构一般如下所示: match variable: #这里的variable是需要判断的内容 case ["quit"]: statement_block_1 # 对应案例的执行代码,当variable="quit"时执行statement_block_1 case ["go", direction]: statement_block_2 case ["drop", *objects]: statement_block_3 ... # 其他的case语句 case _: #如果上面的case语句没有命中,则执行这个代码块,类似于Switch的default statement_block_default 一个match语句的使用示例: def http_error(status): match status: case 400: return "Bad request" case 404: return "Not found" case 418: return "I'm a teapot" case _: return "Something's wrong...
2024-04-01
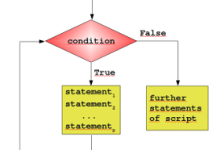
本章节将为大家介绍 Python 循环语句的使用。 Python 中的循环语句有 for 和 while。 Python 循环语句的控制结构图如下所示: while 循环 Python 中 while 语句的一般形式: while 判断条件: statements 同样需要注意冒号和缩进。另外,在Python中没有 do-while 循环。 以下实例使用了 while 来计算 1 到 100 的总和: #!/usr/bin/env python3 n = 100 sum = 0 counter = 1 while counter <= n: sum = sum + counter counter += 1 print('Sum of 1 until %d: %d' % (n,sum)) 尝试一下 执行结果如下: Sum of 1 until 100: 5050 for 语句 Python for 循环可以遍历任何序列的项目,如一个列表或者一个字符串。 for 循环的一般格式如下: for <variable> in <sequence>: <statements> else: <statements> Python for循环实例: >>> languages = ["C", "C++", "Perl", "Python"] >>> for x in languages: ... print (x) ... C C++ Perl Python >>> 以下 for 实例中使用了 break 语句,break 语句用于跳出当前循环体: #!/usr/bin/env python3 edibles = ["ham", "spam","eggs","nuts"] for food in...
2024-04-01