Python3 教程 第5页 本节介绍了 Python3 中的内置函数以及调试的两种方法。 内置函数 abs() dict() help() min() setattr() all() dir() hex() next() slice() any() divmod() id() object() sorted() ascii() enumerate() input() oct() staticmethod() bin() eval() int() open() str() bool() exec() isinstance() ord() sum() bytearray() filter() issubclass() pow() super() bytes() float() iter() print() tuple() callable() format() len() property() type() chr() frozenset() list() range() vars() classmethod() getattr() locals() repr() zip() compile() globals() map() reversed() __import__() complex() hasattr() max() round() delattr() hash() memoryview() set() Python 调试方法 1、print print('here') # 可以发现某段逻辑是否执行 # 打印出变量的内容 2、assert assert false, 'blabla' # 如果条件不成立,则打印出 'blabla' 并抛出AssertionError异常 3、debugger 可以通过 pdb、IDE 等工具进行调试。 调试的具体方法这里不展开。 Python 中有两个内置方法在这里也很有帮助: locals: 执行 locals() 之后, 返回一个字典, 包含(current scope)当前范围下的局部变量。 globals: 执行 globals() 之后, 返回一个字典, 包含(current scope)当前范围下的全局变量。
2024-04-01
MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。 MongoDB 数据库安装与介绍可以查看我们的 MongoDB 教程。 PyMongo Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。 pip 安装 pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。 安装 pymongo: $ python3 -m pip3 install pymongo 也可以指定安装的版本: $ python3 -m pip3 install pymongo==3.5.1 更新 pymongo 命令: $ python3 -m pip3 install --upgrade pymongo easy_install 安装 旧版的 Python 可以使用 easy_install 来安装,easy_install 也是 Python 包管理工具。 $ python -m easy_install pymongo 更新 pymongo 命令: $ python -m easy_install -U pymongo 测试 PyMongo 接下来我们可以创建一个测试文件 demo_test_mongodb.py,代码如下: demo_test_mongodb.py 文件代码: #!/usr/bin/python3 import pymongo 执行以上代码文件,如果没有出现错误,表示安装成功。 创建数据库 创建一个数据库 创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。 如下实例中,我们创建的数据库 w3cschool : 实例 #!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["w3cschool"] 注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。 判断数据库是否已存在 我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在: 实例 #!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient('mongodb://localhost:27017/')...
2024-04-01
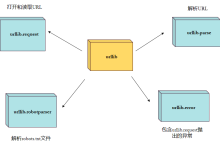
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。 本文主要介绍 Python3 的 urllib。 urllib 包 包含以下几个模块: urllib.request – 打开和读取 URL。 urllib.error – 包含 urllib.request 抛出的异常。 urllib.parse – 解析 URL。 urllib.robotparser – 解析 robots.txt 文件。 urllib.request urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。 urllib.request 可以模拟浏览器的一个请求发起过程。 我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url:url 地址。 data:发送到服务器的其他数据对象,默认为 None。 timeout:设置访问超时时间。 cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。 cadefault:已经被弃用。 context:ssl.SSLContext类型,用来指定 SSL 设置。 实例如下: from urllib.request import urlopen myURL = urlopen("https://www.w3cschool.cn/") print(myURL.read()) 以上代码使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。 read() 是读取整个网页内容,我们可以指定读取的长度: from urllib.request import urlopen myURL = urlopen("https://www.w3cschool.cn/") print(myURL.read(300)) 除了 read() 函数外,还包含以下两个读取网页内容的函数: readline() – 读取文件的一行内容 from urllib.request import urlopen myURL = urlopen("https://www.w3cschool.cn/") print(myURL.readline()) #读取一行内容 readlines() – 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。 from urllib.request import urlopen myURL = urlopen("https://www.w3cschool.cn/") lines =...
2024-04-01
本文主要介绍如何部署简单的 WSGI 应用和常见的 Web 框架。 以 Ubuntu/Debian 为例,先安装依赖包: apt-get install build-essential python-dev Python 安装 uWSGI 1、通过 pip 命令: pip install uwsgi 2、下载安装脚本: curl http://uwsgi.it/install | bash -s default /tmp/uwsgi 将 uWSGI 二进制安装到 /tmp/uwsgi ,你可以修改它。 3、源代码安装: wget http://projects.unbit.it/downloads/uwsgi-latest.tar.gz tar zxvf uwsgi-latest.tar.gz cd uwsgi-latest make 安装完成后,在当前目录下,你会获得一个 uwsgi 二进制文件。 第一个 WSGI 应用 让我们从一个简单的 “Hello World” 开始,创建文件 foobar.py,代码如下: def application(env, start_response): start_response('200 OK', [('Content-Type','text/html')]) return [b"Hello World"] uWSGI Python 加载器将会搜索的默认函数 application 。 接下来我们启动 uWSGI 来运行一个 HTTP 服务器,将程序部署在HTTP端口 9090 上: uwsgi --http :9090 --wsgi-file foobar.py 添加并发和监控 默认情况下,uWSGI 启动一个单一的进程和一个单一的线程。 你可以用 –processes 选项添加更多的进程,或者使用 –threads 选项添加更多的线程 ,也可以两者同时使用。 uwsgi --http :9090 --wsgi-file foobar.py --master --processes 4 --threads 2 以上命令将会生成 4 个进程, 每个进程有 2 个线程。 如果你要执行监控任务,可以使用 stats 子系统,监控的数据格式是 JSON: uwsgi --http :9090 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191 我们可以安装 uwsgitop(类似 Linux top 命令)...
2024-04-01
pip 是 Python 包管理工具,该工具提供了对 Python 包的查找、下载、安装、卸载的功能。 软件包也可以在 https://pypi.org/ 中找到。 目前最新的 Python 版本已经预装了 pip。 查看是否已经安装 pip 可以使用以下命令: pip --version 下载安装包使用以下命令: pip install some-package-name 例如我们安装 numpy 包: pip install numpy 我们也可以轻易地通过以下的命令来移除软件包: pip uninstall some-package-name 例如我们移除 numpy 包: pip uninstall numpy 如果要查看我们已经安装的软件包,可以使用以下命令: pip list
2024-04-01
Python2.x 版本中,使用 cmp() 函数来比较两个列表、数字或字符串等的大小关系。 Python 3.X 的版本中已经没有 cmp() 函数,如果你需要实现比较功能,需要引入 operator 模块,适合任何对象,包含的方法有: operator.lt(a, b) operator.le(a, b) operator.eq(a, b) operator.ne(a, b) operator.ge(a, b) operator.gt(a, b) operator.__lt__(a, b) operator.__le__(a, b) operator.__eq__(a, b) operator.__ne__(a, b) operator.__ge__(a, b) operator.__gt__(a, b) operator.lt(a, b) 与 a < b 相同, operator.le(a, b) 与 a <= b 相同,operator.eq(a, b) 与 a == b 相同,operator.ne(a, b) 与 a != b 相同,operator.gt(a, b) 与 a > b 相同,operator.ge(a, b) 与 a >= b 相同。 # 导入 operator 模块 import operator # 数字 x = 10 y = 20 print("x:",x, ", y:",y) print("operator.lt(x,y): ", operator.lt(x,y)) print("operator.gt(y,x): ", operator.gt(y,x)) print("operator.eq(x,x): ", operator.eq(x,x)) print("operator.ne(y,y): ", operator.ne(y,y)) print("operator.le(x,y): ", operator.le(x,y)) print("operator.ge(y,x): ", operator.ge(y,x)) print() # 字符串 x = "Google" y = "w3cschool" print("x:",x, ", y:",y) print("operator.lt(x,y): ", operator.lt(x,y)) print("operator.gt(y,x): ", operator.gt(y,x)) print("operator.eq(x,x): ", operator.eq(x,x)) print("operator.ne(y,y): ", operator.ne(y,y)) print("operator.le(x,y): ", operator.le(x,y)) print("operator.ge(y,x): ", operator.ge(y,x)) print() # 查看返回值 print("type((operator.lt(x,y)): ", type(operator.lt(x,y))) 以上代码输出结果为:...
2024-04-01
Python 的math 模块提供了许多数学运算函数。为我们进行数学运算提供了便利。 一般情况下math 模块的函数的返回值均为浮点数,除非另有明确说明。 如果你需要计算复数,使用 cmath 模块是一个更好的选择。 cmath模块中拥有与math模块相同的所有函数,它们的区别在于能否进行复数运算。 要使用 math 函数必须先导入: import math 查看 math 模块中的内容: >>> import math >>> dir(math) ['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'comb', 'copysign', 'cos', 'cosh', 'degrees', 'dist', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'isqrt', 'lcm', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'nextafter', 'perm', 'pi', 'pow', 'prod', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc', 'ulp'] math 模块常量 常量 描述 math.e 返回欧拉数 (2.7182…) math.inf 返回正无穷大(这是一个浮点数) math.nan 返回一个浮点值 NaN (not a number,即一个非法数值) math.pi π 一般指圆周率。 圆周率 PI (3.1415…) math.tau 数学常数 τ = 6.283185…,精确到可用精度。Tau 是一个圆周常数,等于 2π,圆的周长与半径之比。 math 模块方法 方法 描述 math.acos(x) 返回 x 的反余弦,结果范围在 0 到...
2024-04-01
通常我们会选择使用request模块来发 送 HTTP 请求。 因为requests 模块比 urllib 模块更简洁。 但requests模块并不是python内置的标准库,我们需要使用pip命令来安装这个模块! pip install requests request的使用相比于urllib简洁了很多,如下所示: # 导入 requests 包 import requests # 发送请求 x = requests.get('https://www.w3cschool.cn/') # 返回网页内容 print(x.text) 每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息。 响应信息如下: 属性或方法 说明 apparent_encoding 编码方式 close() 关闭与服务器的连接 content 返回响应的内容,以字节为单位 cookies 返回一个 CookieJar 对象,包含了从服务器发回的 cookie elapsed 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 encoding 解码 r.text 的编码方式 headers 返回响应头,字典格式 history 返回包含请求历史的响应对象列表(url) is_permanent_redirect 如果响应是永久重定向的 url,则返回 True,否则返回 False is_redirect 如果响应被重定向,则返回 True,否则返回 False iter_content() 迭代响应 iter_lines() 迭代响应的行 json() 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) links 返回响应的解析头链接 next 返回重定向链中下一个请求的 PreparedRequest 对象 ok 检查 “status_code” 的值,如果小于400,则返回 True,如果不小于 400,则返回 False raise_for_status() 如果发生错误,方法返回一个 HTTPError 对象 reason 响应状态的描述,比如 “Not Found” 或 “OK” request 返回请求此响应的请求对象 status_code 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) text 返回响应的内容,unicode 类型数据 url 返回响应的 URL # 导入 requests...
2024-04-01
Python random 模块主要用于生成随机数。 random 模块实现了各种分布的伪随机数生成器。 要使用 random 函数必须先导入: import random 查看 random 模块中的内容: >>> import random >>> dir(random) ['BPF', 'LOG4', 'NV_MAGICCONST', 'RECIP_BPF', 'Random', 'SG_MAGICCONST', 'SystemRandom', 'TWOPI', '_Sequence', '_Set', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_accumulate', '_acos', '_bisect', '_ceil', '_cos', '_e', '_exp', '_floor', '_inst', '_log', '_os', '_pi', '_random', '_repeat', '_sha512', '_sin', '_sqrt', '_test', '_test_generator', '_urandom', '_warn', 'betavariate', 'choice', 'choices', 'expovariate', 'gammavariate', 'gauss', 'getrandbits', 'getstate', 'lognormvariate', 'normalvariate', 'paretovariate', 'randbytes', 'randint', 'random', 'randrange', 'sample', 'seed', 'setstate', 'shuffle', 'triangular', 'uniform', 'vonmisesvariate', 'weibullvariate'] 接下来我们使用 random() 方法返回一个随机数,它在 [0,1) 范围内,包含 0 但不包含 1。 # 导入 random 包 import random # 生成随机数 print(random.random()) 以上实例输出结果为: 0.4784904215869241 seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。 #!/usr/bin/python3 import random random.seed() print ("使用默认种子生成随机数:", random.random()) print ("使用默认种子生成随机数:", random.random()) random.seed(10) print ("使用整数 10 种子生成随机数:", random.random()) random.seed(10) print ("使用整数 10 种子生成随机数:", random.random()) random.seed("hello",2) print ("使用字符串种子生成随机数:", random.random()) 以上实例运行后输出结果为: 使用默认种子生成随机数:...
2024-04-01
很多人抱怨pip安装库有些时候太慢了,那是pip源的问题。 前面说过pip从PyPi中下载库文件,但由于PyPi服务器在国外,访问起来很慢。 但国内提供了很多镜像源,用来替代PyPi,像清华源、豆瓣源、阿里云源等。 这些镜像源备份了PyPi里的数据,由于服务器在国内,速度会快很多。 但镜像源数据有滞后性,比如说清华源的pypi 镜像每 5 分钟同步一次。 使用镜像源有两种方式,以清华源为例: (1) 临时使用 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package matplotlib 除了matplotlib是要安装的库名外,其他都是固定格式 (2) 设为默认 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 设为默认后,以后安装库都是从清华源下载,而且无需再加镜像源网址 附主流镜像源地址 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:http://pypi.hustunique.com/ 山东理工大学:http://pypi.sdutlinux.org/ 豆瓣:http://pypi.douban.com/simple/
2024-04-01