



在判定机器采用大端还是小端存储时,可以按字节输出某数据对象的机器表示的位模式。机器表示的位模式即某数据对象在内存中的二进制串。下面是访问数据对象位模式的一个方法:
//传入一个数据对象,从低地址到高地址按字节输出这个对象的每字节的十六进制表示
void printByte(unsigned char* a,int n)
{
for( int i=0; i<n; i++ ) {
printf("%x ",a[i]);
}
printf("\n");
}
我们定义一个int变量并打印它的位模式:
int x = 128; printByte((unsigned char*)&x,sizeof(int))
可以看到输出为:

上面的输出也表示,这里实验的机器使用小端存储,即数据对象的低位部分存储在低地址部分。
在printByte函数中,需要注意:char* 型的指针指向的同样是一字节大小的数据,但此处一定要用unsigned char* 类型,而不能用char* 类型。因为”%x”是以十六进制形式输出int型的变量,所以,如果printByte的参数设置为char* 类型,在使用%x输出时,会将char类型隐式转换为int类型。此时,在上面的例子中,x值为128,其低8位的位模式为:1000 0000,即0x80,对于char型变量,其真值为-128。转换成int型变量后,位模式为:1111 1111 1111 1111 1111 1111 1000 0000 (补码编码),即0xffffff80:
void printByte(char* a,int n)
{
for( int i=0; i<n; i++ ) {
printf("%x ",a[i]);
}
printf("\n");
}
int main()
{
int x = 128;
printByte((char*)&x,sizeof(int));
return 0;
}
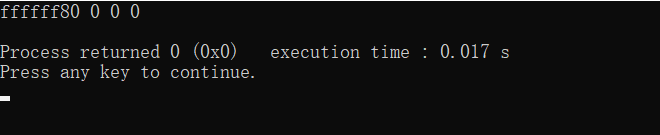
所以,在这个方法打印内存的位模式时,参数指针一定是unsigned char* 类型,而不能是char*类型。













