为什么使用lua脚本为什么能合并多个原子操作?
EVAL script numkeys key [key ...] arg [arg ...]
redis> EVAL “return { KEYS[1], KEYS[2], ARGV[1], ARGV[2], ARGV[3] }” 2 key1 key2 arg1 arg2 arg3
1) “key1”
2) “key2”
3) “arg1”
4) “arg2”
5) “arg3”
但这种方式需要每次都传入 Lua 脚本字符串,不仅浪费网络开销,同时 Redis 需要每次重新编译 Lua 脚本,对于我们追求性能极限的系统来说,不是很完美。所以这里就要说到另一个命令 EVALSHA 了,原生语法如下:
EVALSHA sha1 numkeys key [key ...] arg [arg ...]
不同的是这里传入的不是脚本字符串,而是一个加密串 sha1。这个 sha1 是从哪来的呢?它是通过另一个命令 SCRIPT LOAD 返回的,该命令是预加载脚本用的。
从脚本与 Redis 交互
可以通过
两者几乎一模一样。两者都执行 Redis 命令及其提供的参数(如果这些参数表示格式正确的命令)。但是,这两个函数之间的区别在于处理运行时错误(例如语法错误)的方式。调用函数引发的错误redis.call()直接返回给执行它的客户端。相反,调用redis.pcall()函数时遇到的错误将返回到脚本的执行上下文,而不是进行可能的处理。
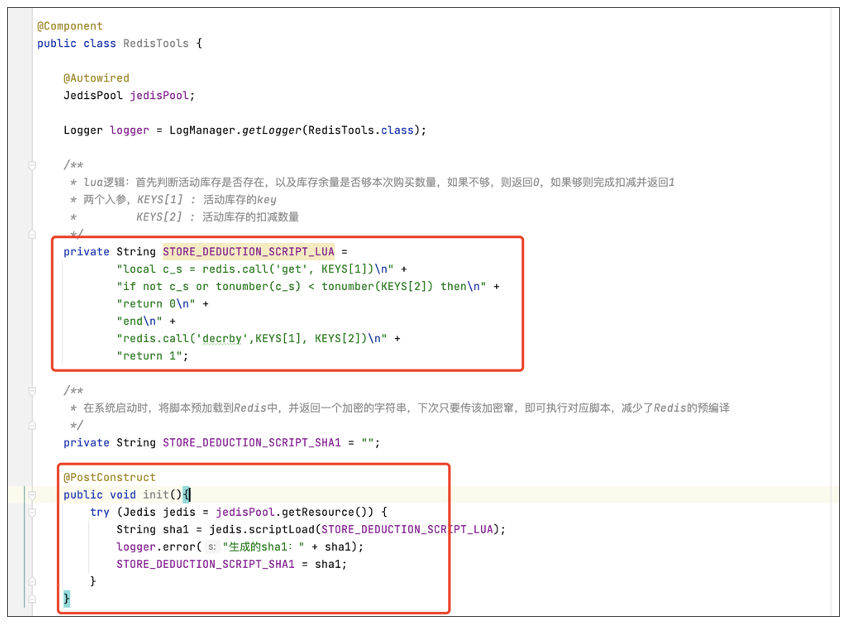
— 调用Redis的get指令,查询活动库存,其中KEYS[1]为传入的参数1,即库存key
local c_s = redis.call(‘get’, KEYS[1])
— 判断活动库存是否充足,其中KEYS[2]为传入的参数2,即当前抢购数量
if not c_s or tonumber(c_s) < tonumber(KEYS[2]) then
return 0
end
— 如果活动库存充足,则进行扣减操作。其中KEYS[2]为传入的参数2,即当前抢购数量
redis.call(‘decrby’,KEYS[1], KEYS[2])
另一种方式是在服务启动时,来完成脚本的预加载,并生成单机全局变量 sha1。我们这里先采取第二种方式,代码结构如下图所示:
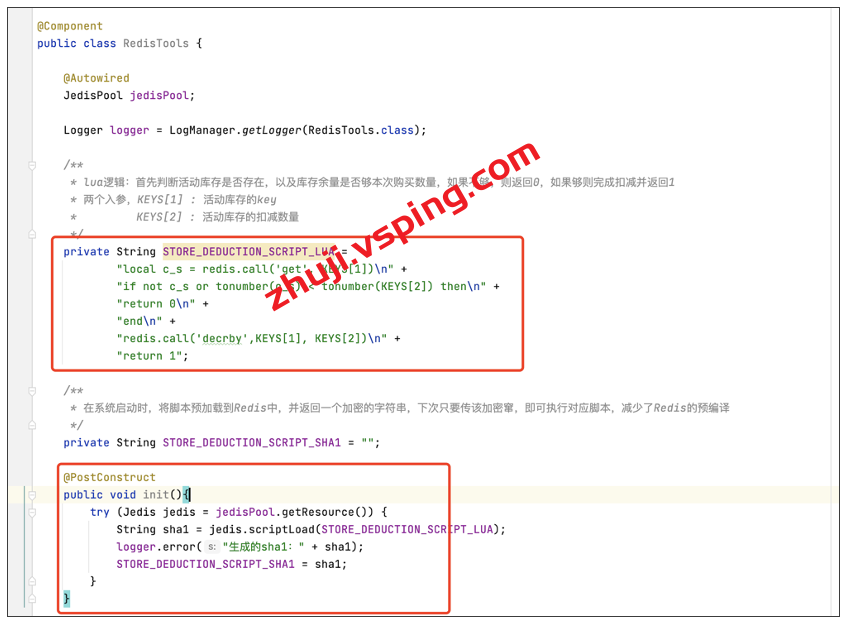
以上是将 Lua 脚本转成字符串形式,并通过 @PostConstruct 完成脚本的预加载。然后新增 EVALSHA 方法,如下图所示:
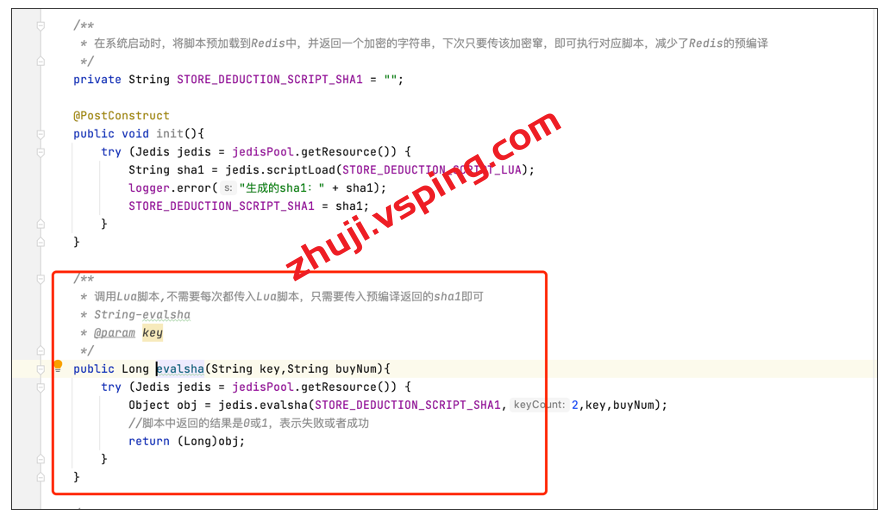
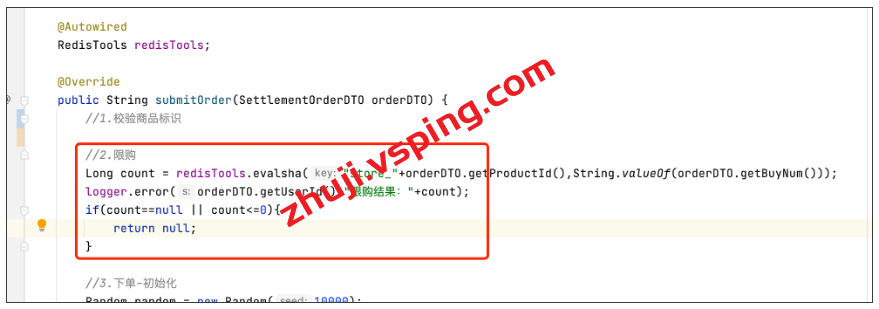
方法入参为活动商品库存 key 以及单次抢购数量,并在内部调用 Lua 脚本执行库存扣减操作。看起来是不是很简单?在写完底层核心方法之后,我们只需要在下单之前,调用该方法即可,具体如下图所示:
脚本缓存
到目前为止,我们已经使用EVAL命令来运行我们的脚本。
每当我们调用时EVAL,我们还会在请求中包含脚本的源代码。重复调用EVAL执行同一套参数化脚本,既浪费网络带宽,也对 Redis 有一定的开销。当然,节省网络和计算资源是关键,因此,Redis 为脚本提供了一种缓存机制。
您执行的每个脚本都EVAL存储在服务器保留的专用缓存中。缓存的内容由脚本的 SHA1 摘要总和组织,因此脚本的 SHA1 摘要总和在缓存中唯一标识它。您可以通过运行EVAL并随后调用来验证此行为INFO。
| SCRIPT FLUSH | 从脚本缓存中移除所有脚本。 |
| SCRIPT LOAD script | 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。 |