



要用Python抓取网页图片,可以使用
requests库来获取网页内容,然后使用
BeautifulSoup库来解析HTML并提取图片链接,接下来,再次使用
requests库下载图片,以下是详细的步骤和代码示例:,1、安装所需库,确保已经安装了
requests和
beautifulsoup4库,如果没有安装,可以使用以下命令安装:,2、导入所需库,在Python脚本中,导入所需的库:,3、获取网页内容,使用
requests.get()方法获取网页内容:,4、解析HTML并提取图片链接,使用
BeautifulSoup解析HTML内容,并提取图片链接:,5、下载图片,遍历图片链接列表,使用
requests.get()方法下载图片,并将其保存到本地:,将以上代码片段组合在一起,即可实现用Python抓取网页图片的功能。,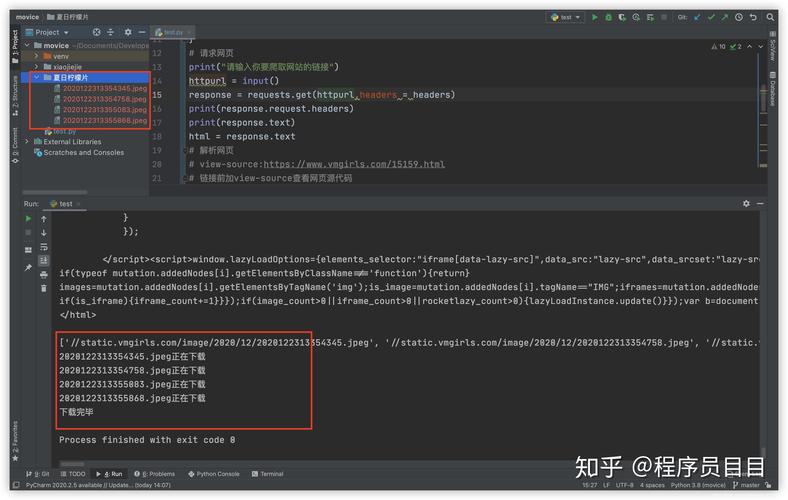
,pip install requests beautifulsoup4,import requests from bs4 import BeautifulSoup import os,url = ‘https://example.com’ # 替换为你要抓取图片的网页链接 response = requests.get(url) html_content = response.text,soup = BeautifulSoup(html_content, ‘html.parser’) img_tags = soup.find_all(‘img’) # 查找所有的<img>标签 img_urls = [img[‘src’] for img in img_tags if ‘src’ in img.attrs] # 提取图片链接,for img_url in img_urls: img_data = requests.get(img_url).content img_name = os.path.basename(img_url) with open(img_name, ‘wb’) as f: f.write(img_data)
如何用python抓取网页图片
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《如何用python抓取网页图片》
文章链接:https://zhuji.vsping.com/440191.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《如何用python抓取网页图片》
文章链接:https://zhuji.vsping.com/440191.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。













