



获取网站的HTML源码是网络爬虫、网站开发和测试等领域的常见需求,HTML源码,即网页的源代码,包含了网页的所有内容和结构,在本文中,我们将详细介绍如何获取网站的HTML源码,包括使用浏览器开发者工具、在线工具和其他编程语言的方法。,1、使用浏览器开发者工具,几乎所有现代浏览器都内置了开发者工具,可以方便地查看和编辑网页的HTML源码,以下是使用Chrome浏览器获取HTML源码的方法:,步骤1:打开目标网站。,步骤2:右键点击页面中的任意位置,然后选择“检查”(Inspect)或按快捷键Ctrl+Shift+I(Windows)或Cmd+Option+I(Mac)。,步骤3:这将打开开发者工具面板,在左侧的导航栏中,点击“Elements”选项卡。,步骤4:现在你可以看到网页的HTML结构,要获取整个页面的HTML源码,只需在右侧的面板中找到并单击最外层的<html>标签,然后右键点击并选择“Copy outerHTML”。,步骤5:将复制的HTML源码粘贴到文本编辑器中,你就可以对其进行查看和编辑了。,2、使用在线工具,除了浏览器开发者工具外,还有一些在线工具可以帮助你获取网站的HTML源码,以下是两个常用的在线工具:,(1)Wappalyzer(https://www.wappalyzer.com/),Wappalyzer是一个网站技术分析工具,可以帮助你识别网站使用的编程语言、框架和库,要使用Wappalyzer获取网站的HTML源码,请按照以下步骤操作:,步骤1:访问Wappalyzer网站。,步骤2:输入目标网站的URL,然后点击“Analyze”按钮。,步骤3:等待分析完成,分析结果将显示在页面上,包括网站使用的技术和编程语言等详细信息。,步骤4:虽然Wappalyzer无法直接提供HTML源码,但它可以帮助你了解网站的结构和技术栈,从而更容易地找到和下载HTML源码。,(2)WebCapture(https://webcapture.net/),WebCapture是一个在线网页截图和录屏工具,但它也提供了获取网站HTML源码的功能,要使用WebCapture获取网站的HTML源码,请按照以下步骤操作:,步骤1:访问WebCapture网站。,步骤2:输入目标网站的URL,然后点击“Start Web Capture”按钮。,步骤3:等待网页加载完成,WebCapture将自动捕获网页的截图和HTML源码。,步骤4:点击“Download HTML”按钮,将HTML源码下载到本地文件中,你可以使用文本编辑器打开和编辑这个文件。,3、使用编程语言,如果你熟悉编程,可以使用Python、JavaScript等编程语言来获取网站的HTML源码,以下是使用Python的requests库和BeautifulSoup库获取网站HTML源码的方法:,以上代码首先导入requests库和BeautifulSoup库,然后定义目标网站的URL,接着,使用requests.get()方法发送HTTP请求,获取网页的内容,之后,使用BeautifulSoup解析HTML内容,提取整个页面的HTML源码,并将其打印出来,你可以将这段代码保存为一个Python文件,然后运行它来获取目标网站的HTML源码。,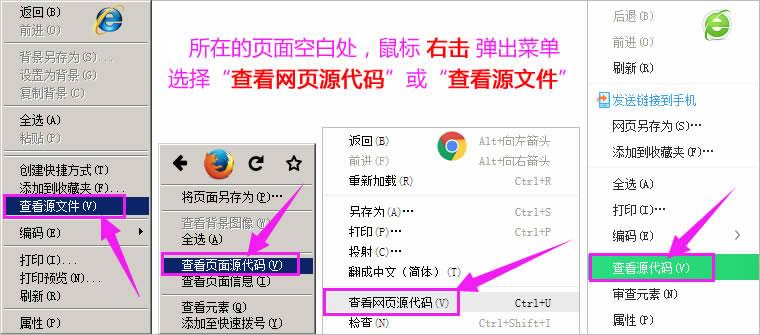
,import requests from bs4 import BeautifulSoup 目标网站的URL url = ‘https://www.example.com’ 发送HTTP请求,获取网页内容 response = requests.get(url) html_content = response.text 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(html_content, ‘html.parser’) 提取整个页面的HTML源码 html_source = soup.prettify() 打印HTML源码 print(html_source),
如何获取网站的html源码
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《如何获取网站的html源码》
文章链接:https://zhuji.vsping.com/438571.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《如何获取网站的html源码》
文章链接:https://zhuji.vsping.com/438571.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。













