linux 任务管理-后台运行与终止 fg、bg、jobs、&、ctrl + z命令 一、 & 加在一个命令的最后,可以把这个命令放到后台执行 ,如gftp &, 二、ctrl + z 可以将一个正在前台执行的命令放到后台,并且处于暂停状态,不可执行 三、jobs 查看当前有多少在后台运行的命令 jobs -l选项可显示所有任务的PID,jobs的状态可以是running, stopped, Terminated,但是如果任务被终止了(kill),shell 从当前的shell环境已知的列表中删除任务的进程标识;也就是说,jobs命令显示的是当前shell环境中所起的后台正在运行或者被挂起的任务信息; 四、fg 将后台中的命令调至前台继续运行 如果后台中有多个命令,可以用 fg %jobnumber将选中的命令调出,%jobnumber是通过jobs命令查到的后台正在执行的命令的序号(不是pid) 五、bg 将一个在后台暂停的命令,变成继续执行 (在后台执行) 如果后台中有多个命令,可以用bg %jobnumber将选中的命令调出,%jobnumber是通过jobs命令查到的后台正在执行的命令的序号(不是pid) 将任务转移到后台运行: 先ctrl + z;再bg,这样进程就被移到后台运行,终端还能继续接受命令。 概念:当前任务 如果后台的任务号有2个,[1],[2];如果当第一个后台任务顺利执行完毕,第二个后台任务还在执行中时,当前任务便会自动变成后台任务号码“[2]” 的后台任务。所以可以得出一点,即当前任务是会变动的。当用户输入“fg”、“bg”和“stop”等命令时,如果不加任何引号,则所变动的均是当前任务 进程的终止 后台进程的终止: 方法一: 通过jobs命令查看job号(假设为num),然后执行kill %num 方法二: 通过ps命令查看job的进程号(PID,假设为pid),然后执行kill pid 前台进程的终止: ctrl+c kill的其他作用 kill除了可以终止进程,还能给进程发送其它信号,使用kill -l 可以察看kill支持的信号。 SIGTERM是不带参数时kill发送的信号,意思是要进程终止运行,但执行与否还得看进程是否支持。如果进程还没有终止,可以使用kill -SIGKILL pid,这是由内核来终止进程,进程不能监听这个信号。 进程的挂起 后台进程的挂起: 在solaris中通过stop命令执行,通过jobs命令查看job号(假设为num),然后执行stop %num; 在redhat中,不存在stop命令,可通过执行命令kill -stop PID,将进程挂起; 当要重新执行当前被挂起的任务时,通过bg %num 即可将挂起的job的状态由stopped改为running,仍在后台执行;当需要改为在前台执行时,执行命令fg %num即可; 前台进程的挂起: ctrl+Z; 以上这篇在Linux中查看及终止正在运行的后台程序方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
我前两天树莓派服务器升级到ubuntu20后, 今天发现服务器的时区不对,定时任务也没启动, python安装的包都丢失。 Docker 的镜像全部丢失。 没办法只能重新来设置了, 这篇文章先说设置时区的问题。 这篇文章中我共找到三种设置时间的方式 tzselect 失效,不知道原因timedatectl 设置成功,推荐使用cp 时区文件的方式, 不建议使用查看时间 现在时间是上午10:41,时区明显不对, 相差8个小时。 使用tzselect 设置, 没有成功 按照提示一路选择: 4) Asia —-> 9) China ——> 1) BeiJing 都没有问题, 我甚至按照最后的提示在 .profile 的最后一行增加了TZ='Asia/Shanghai' 并且断开了ssh连接后重新登录上去, 时间设置还是没成功。 timedatectl 经过搜索发现这个工具 timedatectl是一个命令行工具,它允许你查看或者修改系统的时间和日期。它在所有现代的基于 System 的 Linux 系统中都可以使用,包括 Ubuntu 20.04. timedatectl 打印当前时区信息 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ukKXLTGM-1589166731775)(/Users/dasouche/Library/Application Support/typora-user-images/image-20200511105339889.png)] 如果不带参数直接运行,会正常打印出时间信息。 timedatectl 查看可以设置的时区 timedatectl list-timezones 带上list-timezones参数运行下,看到如下的结果: ubuntu@ubuntu ~ % timedatectl list-timezones Africa/Abidjan Africa/Accra Africa/Algiers Africa/Bissau Africa/Cairo Africa/Casablanca Africa/Ceuta Africa/El_Aaiun Africa/Johannesburg Africa/Juba Africa/Khartoum Africa/Lagos Africa/Maputo Africa/Monrovia Africa/Nairobi Africa/Ndjamena Africa/Sao_Tome Africa/Tripoli Africa/Tunis Africa/Windhoek America/Adak America/Anchorage America/Araguaina America/Argentina/Buenos_Aires America/Argentina/Catamarca America/Argentina/Cordoba America/Argentina/Jujuy America/Argentina/La_Rioja America/Argentina/Mendoza America/Argentina/Rio_Gallegos America/Argentina/Salta America/Argentina/San_Juan America/Argentina/San_Luis America/Argentina/Tucuman America/Argentina/Ushuaia America/Asuncion America/Atikokan America/Bahia America/Bahia_Banderas America/Barbados America/Belem America/Belize America/Blanc-Sablon America/Boa_Vista America/Bogota America/Boise America/Cambridge_Bay America/Campo_Grande America/Cancun America/Caracas America/Cayenne America/Chicago America/Chihuahua America/Costa_Rica America/Creston America/Cuiaba lines 1-56 上面的结果展示不全, 往下翻找可以看到 Asia/Shanghai 这一行. timedatectl...
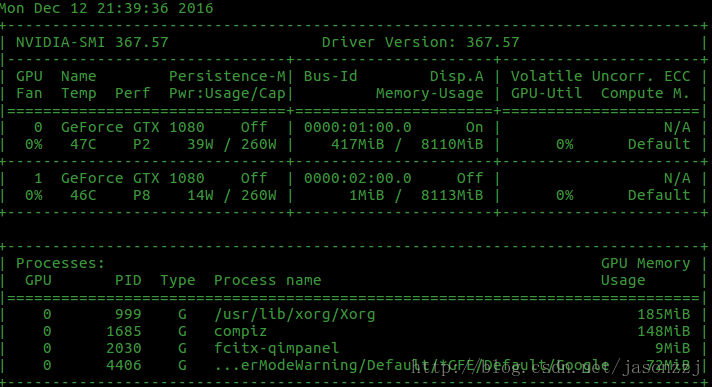
在使用TensorFlow跑深度学习的时候,经常出现显存不足的情况,所以我们希望能够随时查看GPU时使用率。如果你是Nvidia的GPU,那么在命令行下,只需要一行命令就可以实现。 1. 显示当前GPU使用情况 Nvidia自带了一个nvidia-smi的命令行工具,会显示显存使用情况: $ nvidia-smi 输出: 2. 周期性输出GPU使用情况 但是有时我们希望不仅知道那一固定时刻的GPU使用情况,我们希望一直掌握其动向,此时我们就希望周期性地输出,比如每 10s 就更新显示。 这时候就需要用到 watch命令,来周期性地执行nvidia-smi命令了。 了解一下watch的功能: $ whatis watch watch(1) - execute a program periodically, showing output fullscreen 作用:周期性执行某一命令,并将输出显示。 watch的基本用法是: $ watch [options] command 最常用的参数是 -n, 后面指定是每多少秒来执行一次命令。 监视显存:我们设置为每 10s 显示一次显存的情况: $ watch -n 10 nvidia-smi 显示如下: 这样,只要开着这个命令行窗口,就可以每十秒刷新一次,是不是很方便呢? 如果我们希望来周期性地执行其他命令行操作,那么就可以简单地更换后面的nvidia-smi即可,So Cool ! 本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
使用apt-get安装时,会很慢,更换了国内的源后,就可以解决这个问题了。 1. 备份sources.list文件 sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak 2. 打开sources.list文件 sudo gedit /etc/apt/sources.list 3. 删除原内容,添加下列内容 #清华源 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiversedeb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse #阿里云源 deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb-src...
有时候我们需要通过在linux上远程运行windows系统上的程序。 方法一: 通过python中的 winrm模块,前提条件,先提前设置好winrm服务。如何设置请自行百度,winRM服务是windows server下PowerShell的远程管理服务。Python脚本通过连接winRM模块操作windows命令行。 import winrm def cmd_views(ip,cmd_comand): win = winrm.Session('http://'+ip+':5985/wsman', auth=('user', 'password'))#参数为用户名和密码 r = win.run_cmd(cmd_comand) # 执行cmd命令= return r.std_out # 打印获取到的信息 ip="xxx.xxx.xx.xx" cmd_comand=r"ipconfig"#运行命令 a=cmd_views(ip, cmd_comand) print(cmd_comand) print(type(a)) print(a) 经过本人测试这个模块只能执行一些简单的命令,就是那种基本上能一输入就能立马响应结果的命令。碰到一些稍微复杂的,进程就挂掉了。 方法二: 通过python中的telnetlib库进行执行操作,前提设置windows系统中的telnet设置,1,安装telnet客户端和服务器端。2配置telnet用户权限,不会就自行百度设置。 # -- coding: utf-8 -- import telnetlib,time def telnetlib_views(ipaddress,user,password,cmdname): tn=telnetlib.Telnet(ipaddress) a=tn.read_until(b'login:') tn.write(user.encode('ascii') + b'\r\n') tn.read_until(b'password:') time.sleep(5) tn.write(password.encode('ascii') + b'\r\n') time.sleep(2) tn.write(cmdname.encode('ascii') + b'\r\n') tn.close() cmdname=r'ifconfig'#运行命令 telnetlib_views(ipaddress="xxx.xxx.xxx.xxx", user="xxx", password="xxxx",cmdname=cmdname) 等待命令调用完成,程序结束。 方法三 利用wmi模块,缺陷只能通过windows-windows,linux-windows行不通,linux相关模块无法安装。 import wmi def sys_version(ipaddress, user, password,cmdname): conn = wmi.WMI(computer=ipaddress, user=user, password=password) try: cmd_callbat = r”cmd /c call %s” % cmdname print(“当前执行bat 命令为:”,cmd_callbat) conn.Win32_Process.Create(CommandLine=cmd_callbat) except Exception as e: print(e) cmdname= r”xxx.bat”#运行命令 sys_version(ipaddress=”xxx.xx.xx.xx”, user=”xx”, password=”xxx”,cmdname=cmdname)# 命令被调用,程序结束,无需等待,区别于方法二,缺陷 无法在linux上安装库 应用场景实用,现在我需要在linux上执行程序,将windows系统上的一个PDF格式的文件,传到linux上? # — coding: utf-8 — import winrm def job(): # 获得连接 t = winrm.Session(“xxx.xx.xx.xx”, auth=(“xx”, “xxx”)) # 获得a.pdf内容 r =...
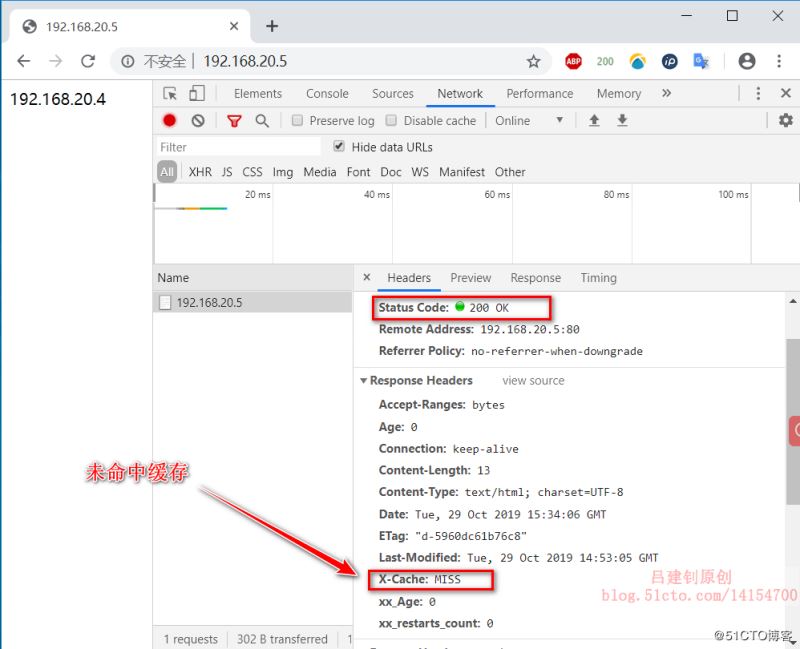
一、varnish简介 Varnish是高性能开源的反向代理服务器和HTTP缓存服务器,其功能与Squid服务器相似,都可以用来做HTTP缓存。可以安装 varnish 在任何web前端,同时配置它缓存内容。与传统的 squid 相比,varnish 具有性能更高、速度更快、管理更加方便等诸多优点。有一部分企业已经在生产环境中使用其作为旧版本的 squid的替代方案,以在相同的服务器成本下提供更好的缓存效果,Varnish 更是作为 CDN 缓存服务器的可选服务之一。 varnish的主要特性如下: 缓存位置:可以使用内存也可以使用磁盘。如果要使用磁盘的话推荐 SSD 做 RAID1; 日志存储:日志也存储在内存中。存储策略:固定大小,循环使用; 支持虚拟内存的使用; 有精确的时间管理机制,即缓存的时间属性控制; 状态引擎架构:在不同的引擎上完成对不同的缓存和代理数据进行处理。可以通过特定的配置语言设计不同的控制语句,以决定数据在不同位置以不同方式缓存,在特定的地方对经过的报文进行特定规则的处理; 缓存管理:以二叉堆格式管理缓存数据,做到数据的及时清理。 varnish与squid相比,都是一个反向代理缓存服务器,并且都是开源的,varnish的稳定性很高,并且访问速度很快,因为Squid是从硬盘读取缓存的数据,而Varnish把数据存放在内存中,直接从读取内存,避免了频繁在内存、磁盘中交换文件,所以Varnish要相对更高效,varnish可以支持更多的并发连接,因为varnish的TCP连接释放要比squid快;varnish也可以通过管理端口,使用正则表达式批量的清除部分缓存,而squid是做不到的;squid 属于是单进程使用单核 CPU,但 Varnish 是通过 fork 形式打开多进程来做处理,所以可以合理的使用所有核来处理相应的请求。 上述说了很多varnish的优点,但是varnish也并非完美,其缺点主要有以下两个: 1、varnish 进程一旦 Crash 或者重启,缓存数据都会从内存中完全释放,此时所有请求都会 发送到后端服务器,在高并发情况下,会给后端服务器造成很大压力; 2、在 varnish 使用中如果单个 url 的请求通过 HA/F5 等负载均衡,则每次请求落在不同的varnish 服务器中,造成请求都会被穿透到后端;而且同样的请求在多台服务器上缓存,也会造成 varnish 的缓存的资源浪费,造成性能下降; Varnish 劣势的解决方案: : 针对劣势一:在访问量很大的情况下推荐使用 varnish 的内存缓存方式启动,而且后面需要跟多台 squid/nginx 服务器。主要为了防止前面的 varnish 服 务、服务器被重启的情况下,大量请求穿透 varnish,这样 squid/nginx 可以就担当第二层 CACHE,而且也弥补了varnish 缓存在内存中重启都会释放的问题; 针对劣势二:可以在负载均衡上做 url 哈希,让单个 url 请求固定请求到一台 varnish 服务器上; 二、Varnish 如何工作 Varnish 的master进程负责启动工作,master进程读取配置文件,根据指定的空间大小(例如管理员分配了2G内存)来创建存储空间,创建并管理child进程; 然后child进程来处理后续任务,它会分配一些线程来执行不同的工作,例如:接受http请求、为缓存对象分配存储空间、清除过期缓存对象、释放空间、碎片整理等。 http请求处理过程如下: 1、有一个专门负责接收http请求的线程,一直监听请求端口,当有请求过来时,负责唤起一个工作线程来处理请求,工作线程会分析http请求的uri,知道了这个请求想要什么,就到缓存中查找是否有这个对象,如果有,就把缓存对象直接返回给用户,如果没有,会把请求转给后端服务器处理,并等待结果,工作线程从后端得到结果内容后,先把内容作为一个缓存对象保存到缓存空间(以备下次请求这个对象时快速响应),然后再把内容返回给用户 分配缓存过程如下: 有一个对象需要缓存时,根据这个对象的大小,到空闲缓存区中查找大小最适合的空闲块,找到后就把这个对象放进去,如果这个对象没有填满这个空闲块,就把剩余的空间做为一个新的空闲块,如果空闲缓存区中没地方了,就要先删除一部分缓存来腾出地方,删除是根据最近最少使用原则。 释放缓存过程如下: 有一个线程来负责缓存的释放工作,他定期检查缓存中所有对象的生存周期,如果某个对象在指定的时间段内没有被访问,就把这个对象删除,释放其占用的缓存空间,释放空间后,检查一下临近的内存空间是否是空闲的,如果是,就整合为一个更大的空闲块,实现空间碎片的整理。 更多varnish特性,请移步至varnish官方网站。 三、部署varnish缓存服务器 环境准备: 三台centos 7.5服务器,IP分别为192.168.20.5、20.4、20.3; 其中IP192.168.20.5为varnish缓存服务器,而另外两台为后端web服务器,分别准备不同的网页文件(我这里将其网页内容更改为其IP),以便验证其缓存效果; 下载我提供的varnish源码包,并上传至varnish服务器。 1、开始部署安装varnish: [root@varnish ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo #下载阿里镜像站的repo文件 [root@varnish ~]# yum -y install libedit-devel pcre-devel python-docutils #安装依赖包 [root@varnish ~]# cd /usr/src #切换至指定目录 [root@varnish src]# rz #上传我提供的varnish源码包 [root@varnish src]# tar zxf varnish-4.0.3.tar.gz #解包 [root@varnish src]# cd...
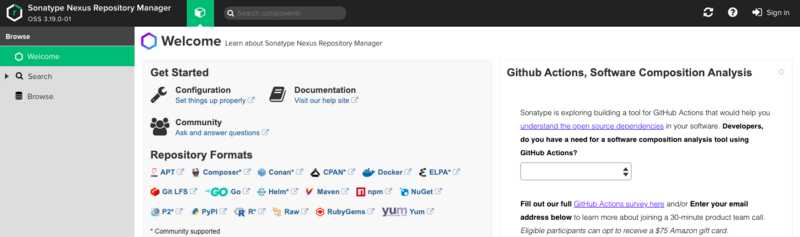
本文介绍如何在Linux服务器通过Docker搭建Nexus私服 一、安装Nexus 1、创建存放数据的位置 # 进入个目录,这个你们随便 cd /srv # 创建个文件夹 mkdir nexus-data # 赋予权限,不然启动会报错,无操作权限 chmod 777 nexus-data 2、启动 执行以下命令即可,会自动拉取镜像并启动 docker run -d -p 8081:8081 --name nexus -v /srv/nexus-data:/nexus-data --restart=always sonatype/nexus3 通过docker logs -f nexus查看启动日志,当出现Started Sonatype Nexus OSS说明启动成功,这时通过http://ip:8081即可访问 点击右上角Sign in进行登录,账号为admin,密码需要去镜像中查看 # 进入镜像 docker exec -it nexus bash # 查看密码,路径在登录框会提示,然后复制即可,登陆成功后会让你修改密码 cat /nexus-data/admin-password 至此,就启动完成了,进入主页后点击左边菜单栏的Browse即可查看你拥有的仓库啦 二、Nexus仓库 1、仓库类型 Nexus有四种仓库和四种仓库类型 a、仓库 仓库名 描述 maven-central maven中央库,默认从https://repo1.maven.org/maven2/拉取jar maven-releases 私库发行版jar maven-snapshots 私库快照(调试版本)jar maven-public 仓库分组,把上面三个仓库组合在一起对外提供服务,在本地maven基础配置settings.xml中使用 b、类型 类型 描述 group(仓库组类型) 用于方便开发人员自己设定的仓库 hosted(宿主类型) 内部项目的发布仓库(内部开发人员,发布上去存放的仓库) proxy(代理类型) 从远程中央仓库中寻找数据的仓库(可以点击对应的仓库的Configuration页签下Remote Storage Location属性的值即被代理的远程仓库的路径) virtual(虚拟类型) 虚拟仓库(这个基本用不到,重点关注上面三个仓库的使用) 2、拉取jar包流程 Maven可直接从宿主仓库下载构件,也可以从代理仓库下载构件,而代理仓库间接的从远程仓库下载并缓存构件,为了方便,Maven可以从仓库组下载构件,而仓库组并没有实际的内容(下图中用虚线表示,它会转向包含的宿主仓库或者代理仓库获得实际构件的内容) 3、创建仓库 进过上面的讲解,我们对仓库已经有了了解,接下来我们进行创建仓库,分为是代理仓库(proxy)、宿主仓库(hosted)、仓库组(group),点击主页上面的小螺丝然后在选择Repositories进入仓库管理列表,然后就可以开始创建我们的仓库啦,选择仓库类型的时候一定要选择maven2 a、proxy代理仓库 我们使用阿里的中央仓库 b、hosted宿主仓库 这里可以创建releases和snapshot类型的仓库,这里就演示一种 c、group仓库组 三、项目配置 前两章走完我们已经在Linux服务器部署好了nexus并且创建好了我们的仓库,接下来我们就来试着在项目中配置 1、创建一个Maven项目 为了演示,就随便创建个工具类玩,以下是目录结构 2、pom文件 这里为了演示我就配了release仓库,实际上应该同时要配置snapshot仓库,maven会判断版本后面是否带了-SNAPSHOT,如果带了就发布到snapshots仓库,否则发布到release仓库 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.gjing</groupId> <artifactId>demo</artifactId> <version>1.0</version> <name>demo</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <distributionManagement> <repository> <!--ID可以随便写,但是要与maven的setting文件中一致--> <id>releases</id> <!--指向仓库类型为hosted(宿主仓库)的储存类型为Release的仓库----> <url>http://你nexus仓库的IP:8081/repository/me-release/</url>...
linux 基础配置 python3的linux环境编译安装 1.linux下安装软件的方式 -首选yum工具,方便,自行解决软件之间的依赖关系,自动下载且安装 1.配置yum源(就是一个软件仓库,里面放了一堆rpm软件包) 可以选择阿里云源,清华yum源 配置第一个仓库,里面有大量系统常用软件 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo 还得配置第二个仓库,携带大量第三方软件(nginx,redis,mongodb,mairadb等) wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo 2.你得了解yum的仓库目录 cd /etc/yum.repos.d/ #在这个目录第一层的repo文件就会被识别问yum软件仓库 3.清空yum缓存,清空centos官方的yum软件缓存 yum clean all 4.生成新的阿里云的yum缓存 yum makecache -wget 在一个资源url的命令 -apt-get ubuntu底下的yum -使用yum仓库,不仅仅可以使用第三方的yum仓库,还是可以指定官方的yum源(好比mariadb数据库的官方yum源,软件包最新) -rpm手动安装,得处理依赖关系 -自由选择版本,且可以扩展第三方功能的安装方式,叫做源码编译安装 查看依赖模块 pip3 freeze > requirements.txt #这个 requirements.txt文件是python程序员都认识的模块依赖文件 第一步.启动mariadb数据库 配置yum源 1.yum 配置yum源 yum install mariadb-server mariadb -y 2.通过yum安装的软件,怎么启动 systemctl start mariadb # systemctl start/stop/status/restart mariadb 3.登陆数据库 cmd登录 导出windows的数据库,导入给linux机器 cmd登录导出命令 mysqldump -uroot -p se_crm > se_crm.sql #指定数据库导出到se_crm.sql这个数据文件中 传输到linux中,进行导入 简单的利用 lrzsz工具传输 或者下载xftp工具 导入数据的命令 mariadb安装 yum install mariadb-server 方式1: 1.创建一个se_crm数据库 create database se_crm; #导入数据的命令 mysql -uroot -p se_crm < /opt/se_crm.sql #指定se_crm数据库,导入一个sql文件 方式2: 登陆数据库之后,用命令导入数据 1.创建一个se_crm数据库 create database se_crm; 2.切换数据库 use se_crm; 3.读取sql文件,写入数据集 mareiadb> source /opt/se_crm.sql; 第二步:准备python3环境,以及虚拟环境 编译安装python3,解决环境变量 centos7下编译安装python3的方式 1.必须解决编译所需的基础开发环境 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel...
说明:可以做SSH免密登录之后执行,这样可以省去每次执行输入密码的提示。 对于简单的命令: 如果是简单执行几个命令,则: ssh user@remoteNode "cd /home ; ls" 基本能完成常用的对于远程节点的管理了,几个注意的点: 双引号,必须有。如果不加双引号,第二个ls命令在本地执行 分号,两个命令之间用分号隔开 多行命令可以输入双引号后回车,结尾使用双引号包裹 对于脚本的方式: 有些远程执行的命令内容较多,单一命令无法完成,考虑脚本方式实现: #!/bin/bash ssh user@remoteNode > /dev/null 2>&1 << eeooff cd /home touch abcdefg.txt exit eeooff echo done! 远程执行的内容在”<< eeooff“至”eeooff“之间,在远程机器上的操作就位于其中,注意的点: << eeooff,ssh后直到遇到eeooff这样的内容结束,eeooff可以随便修改成其他形式。 重定向目的在于不显示远程的输出了 在结束前,加exit退出远程节点 执行本地的脚本 我们在本地创建一个脚本文件test.sh,内容为: ls pwd echo $0 然后运行下面的命令: ssh root@xxx.xxx.xxx.xxx < test.sh 带参数本地脚本 ssh root@xxx.xxx.xxx.xxx 'bash -s' < test.sh helloworld 执行远程服务器上的脚本 ssh root@xxx.xxx.xxx.xxx "/home/nick/test.sh" 执行远程服务器上带参数的脚本 ssh root@xxx.xxx.xxx.xxx /home/nick/test.sh helloworld 总结 以上所述是小编给大家介绍的Linux下使用SSH远程执行命令方法收集,大家如有疑问可以留言,或者联系站长。感谢亲们支持!!! 如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
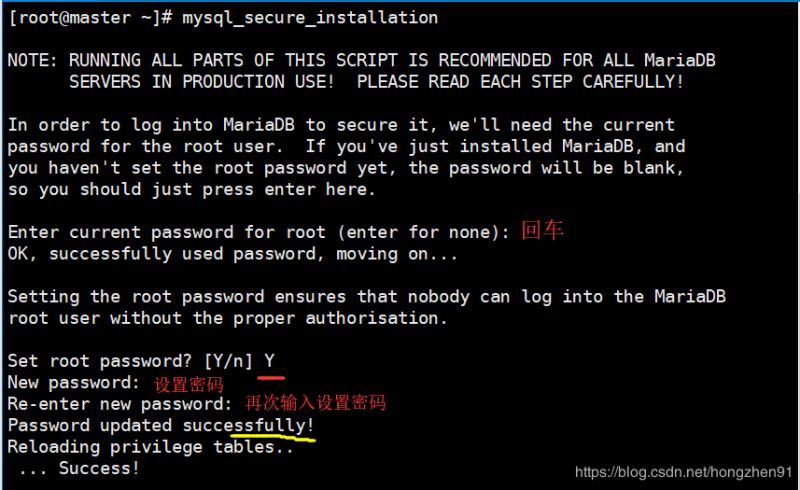
CentOS 6 及之前的版本中提供的是 MySQL 的服务器/客户端安装包,但 CentOS 7 已使用了 MariaDB 替代了默认的 MySQL。MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。 1、删除自带 MySQL/MariaDB 1.1、搜索 MariaDB 现有包 使用rpm -qa | grep mariadb搜索 MariaDB 现有的包。如果存在,使用 rpm -e –nodeps mariadb-* 全部删除: [root@master ~]# rpm -qa | grep mariadb mariadb-server-5.5.52-1.el7.x86_64 mariadb-libs-5.5.52-1.el7.x86_64 [root@localhost ~]# rpm -e mysql-* 错误:未安装软件包 mysql-* 1.2、移除 MariaDB 现有包 如果存在,使用 yum remove mysql mysql-server mysql-libs compat-mysql51 全部删除: [root@master ~]# yum remove mysql mysql-server mysql-libs compat-mysql51 已加载插件:fastestmirror, langpacks 参数 mysql 没有匹配 参数 mysql-server 没有匹配 参数 compat-mysql51 没有匹配 正在解决依赖关系 –> 正在检查事务 —> 软件包 mariadb-libs.x86_64.1.5.5.52-1.el7 将被 删除 –> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 perl-DBD-MySQL-4.023-5.el7.x86_64 需要 –> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 2:postfix-2.10.1-6.el7.x86_64 需要 –> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 1:qt-mysql-4.8.5-13.el7.x86_64 需要………. 删除: mariadb-libs.x86_64 1:5.5.52-1.el7 作为依赖被删除: akonadi-mysql.x86_64 0:1.9.2-4.el7 mariadb-server.x86_64 1:5.5.52-1.el7 perl-DBD-MySQL.x86_64 0:4.023-5.el7 postfix.x86_64 2:2.10.1-6.el7 qt-mysql.x86_64 1:4.8.5-13.el7 完毕! [root@master ~]# rpm -qa|grep mariadb [root@master ~]# 2、MariaDB 安装 2、Server...